디멘의 블로그
Dimen's Blog
이데아를 여행하는 히치하이커
Alice in Logicland
Łoś's Theorem
25 Jan 2025This post continues from the previous post.
5. Nonstandard Characteristics of Hypernatural Numbers
The hypernatural numbers we have examined so far — $[0], [1], [2], \dots$ — correspond to standard natural numbers. We shall now examine some bizarre hypernatural numbers.
Consider the following hypernatural number $\mathfrak{n}$:
\[\mathfrak{n} = [(1, 2, 3, 4, \dots)]\]Recalling how binary relation is defined for hypernaturals, for any natural number $n$, we have $[n] < \mathfrak{n}$. That is, $\mathfrak{n}$ is a hypernatural number greater than all natural numbers. That is, the following holds for hypernaturals:
\[\phi_1 : \exists x \; ( \lbrace y : y < x \rbrace \text{ is infinite } )\]This sentence does not hold in the natural numbers.
Now consider the following hypernatural number $\mathfrak{m}$:
\[\mathfrak{m} = [(1, 2!, 3!, 4!, \dots)]\]For any standard natural number $n$, $\mathfrak{m}$ is divisible by $[n]$. That is, $\mathfrak{m}$ has every natural number as a divisor. Therefore, the following holds for hypernaturals:
\[\phi_2 : \exists x \; (\lbrace y : y \mid x \rbrace \text{ is infinite })\]Again, this sentence does not hold in the natural numbers.
This may seem to contradict the promise delivered in the previous essay. There, I stated that the natural numbers and hypernatural numbers are logically indistinguishable. Yet $\phi_1$ and $\phi_2$, both of which seem to be a cogent logical formula, are true in $\mathbb{N}^*$ but false in $\mathbb{N}$. Have I been misleading?
Of course not. The key to this apparent paradox lies in the fact that $\phi_1$ and $\phi_2$ cannot be expressed in first-order logic. By the compactness theorem, “… is finite” is inexpressible in first-order logic.
For a more precise statement, let us define the following:
Definition. Two $\mathcal{L}$-models $\mathcal{M}_1$ and $\mathcal{M}_2$ of a language $\mathcal{L}$ are elementarily equivalent if for any $\mathcal{L}$-sentence $\phi$,
\[\mathcal{M_1} \vDash \phi \iff \mathcal{M}_2 \vDash \phi\]
Theorem. $\mathbb{N}$ and $\mathbb{N}^*$ are elementarily equivalent.
This theorem is a special case of Łoś’s theorem. But before we state Łoś’s theorem, let us first rigorously define ultraproducts.
6. Ultraproducts
Let a set $I$ and a free ultrafilter $\mathcal{U}$ on $I$ be given. Furthermore, let models $\lbrace \mathcal{M}_i \rbrace_{i \in I}$ of a language $\mathcal{L}$ be given. We define the ultraproduct $\mathcal{M}^* = \prod \mathcal{M}_i / \mathcal{U}$ as follows:
Elements of the Ultraproduct
The elements of $\mathcal{M}^*$ are equivalence classes of $\lbrace (a_i)_{i\in I} : a_i \in \mathcal{M}_i \rbrace$ under the relation $\sim$, where $\sim$ is defined as:
\[(a_i)_{i\in I} \sim (b_i)_{i \in I} \iff \lbrace i \in I : a_i = b_i \rbrace \in \mathcal{U}\]Operations on the Ultraproduct
Let $f(x)$ be a function in $\mathcal{L}$. For an element $\mathfrak{a} = [(a_i)_{i\in I}]$ of $\mathcal{M}^*$, we define:
\[f(\mathfrak{a}) = [(f(a_i))_{i \in I}]\]This definition generalises naturally to $n$-ary functions.
Relations on the Ultraproduct
Let $P(x, y)$ be a relation in $\mathcal{L}$. For two elements $\mathfrak{a} = [(a_i)_{i\in I}]$ and $\mathfrak{b} = [(b_i)_{i\in I}]$ of $\mathcal{M}^*$, we define:
\[\mathcal{M}^* \vDash P(\mathfrak{a}, \mathfrak{b}) \iff \lbrace i \in I : \mathcal{M}_i \vDash P(a_i, b_i) \rbrace \in \mathcal{U}\]This definition generalises naturally to $n$-ary predicates.
When defining operations and relation on the ultraproduct, one needs to show that the definition is irrelevant to which element is chosen as a representative for each equivalence class. This follows readily from the intersection property of $\mathcal{U}$, so we leave it as an exercise.
We can now redefine the hypernatural numbers as the ultraproduct arising when $I, \mathcal{U}, \mathcal{L}, \mathcal{M}_i$ are respectively:
- $I = \mathbb{N}$
- $\mathcal{U} =$ Fréchet ultrafilter
- $\mathcal{L} = (0, S, <)$
- $\mathcal{M}_i = \mathbb{N}$
Similarly, we can define the hyperreal numbers:
- $I = \mathbb{N}$
- $\mathcal{U} =$ Fréchet ultrafilter
- $\mathcal{L} = (0, 1, +, ⋅, <)$
- $\mathcal{M}_i = \mathbb{R}$
7. Łoś’s Theorem
Łoś’s Theorem. Given an ultraproduct $\mathcal{M}^* = \prod \mathcal{M}_i / \mathcal{U}$, for any $\mathcal{L}$-sentence $\phi$, the following holds:
\[\mathcal{M}^* \vDash \phi \iff \lbrace i \in I : \mathcal{M}_i \vDash \phi \rbrace \in \mathcal{U}\]
Proof. We prove this by structural induction on $\phi$.
1. $\phi$ is an atomic proposition
This follows trivially from the definition of predicates on ultraproducts.
2. $\phi := \psi \land \theta$
\[\begin{aligned} &\mathcal{M}^* ⊨ φ\\ &\iff \mathcal{M}^* ⊨ ψ \land \mathcal{M}^* ⊨ θ\\ &\iff \lbrace i ∈ I \mid \mathcal{M}_i ⊨ ψ \rbrace ∈ \mathcal{U} \land \lbrace i ∈ I \mid \mathcal{M}_i ⊨ θ \rbrace ∈ \mathcal{U} &&(*) \\ &\iff \lbrace i ∈ I \mid \mathcal{M}_i ⊨ ψ \rbrace \cap \lbrace i ∈ I \mid \mathcal{M}_i ⊨ θ \rbrace ∈ \mathcal{U} &&(**) \\ &\iff \lbrace i ∈ I \mid \mathcal{M}_i ⊨ ψ \land \mathcal{M}_i ⊨ θ \rbrace ∈ \mathcal{U}\\ &\iff \lbrace i ∈ I \mid \mathcal{M}_i ⊨ ψ∧θ \rbrace ∈ \mathcal{U}\\ &\iff \lbrace i ∈ I \mid \mathcal{M}_i ⊨ φ \rbrace ∈ \mathcal{U} \end{aligned}\]$(*)$ holds by the inductive hypothesis, and $(**)$ holds by the intersection closure property of $\mathcal{U}$.
3. $\phi := \lnot \psi$
This can be proved by a similar method to case 2, using the inductive hypothesis and the ultrafilter property of $\mathcal{U}$ ($A \in \mathcal{U} \lor A^c \in \mathcal{U}$).
4. $\phi := \exists x\; \psi$
This can be proved by a similar method to case 2, though the inductive hypothesis alone suffices.
Since every proposition can be constructed from cases 1, 2, 3, and 4, the theorem is proved by induction. ■
Corollary. $\mathbb{N}$ and $\mathbb{N}^*$ are elementarily equivalent.
Proof. By Łoś’s theorem, the necessary and sufficient condition for $\mathbb{N}^* \vDash \phi$ is that $\lbrace i \in \mathbb{N} : \mathbb{N}^\ast_i \vDash \phi \rbrace \in \mathcal{U}$. However, since $\mathbb{N}^*_i = \mathbb{N}$, the necessary and sufficient condition reduces to $\mathbb{N} \vDash \phi$. ■
프레셰 필터와 비표준 자연수
22 Jan 2025뢰벤하임-스콜렘 정리에 따르면 표준 산술 모형과 초등적으로 동등elementarily equivalent하지만 구조적으로 상이nonisomorphic한 모형이 존재한다. 달리 말해, 자연수가 만족하는 모든 1차 논리 명제를 만족하지만 자연수가 아닌 수 체계가 존재한다.
이 글에서는 초곱ultraproduct을 이용하여 대표적인 산술의 비표준적 모형인 초자연수hypernaturals를 구성하고, 이것이 표준 산술 모형과 초등적으로 동등함을 보증하는 워시의 정리Łoś’s theorem를 증명한다.
1. 개괄
콤팩트성 정리에 의해 우리는 1차 논리가 유한과 무한을 구별하지 못함을 안다. 따라서 무한을 적절히 사용함으로써 자연수와 1차 논리적으로 구분 불가능한 모델을 정의할 수 있으리라 기대해봄직하다.
이에 따라 다음과 같이 초자연수 $[0], [1], [2], \dots$를 정의하자.
\[\begin{aligned} [][0] &= (0, 0, 0, 0, 0, \dots) \\ [1] &= (1, 1, 1, 1, 1, \dots) \\ [2] &= (2, 2, 2, 2, 2, \dots) \end{aligned}\]그런데 생각해 보면 모든 항이 0으로 차 있어야 $[0]$으로 간주하는 것은 지나치게 엄격하다. 예를 들어 처음 두 개의 항만 1이고 나머지 항은 모두 0인 튜플 $(1, 1, 0, 0, 0, \dots)$ 또한 $[0]$으로 보는 것이 자연스럽다. 따라서 유한 개의 항을 제외한 모든 항이 $n$이라면 그 튜플 또한 $[n]$으로 간주하도록 하자. 즉,
\[[n] = \lbrace (x_1, x_2, x_3, \dots) \in \mathbb{N}^\omega : \lbrace i \in \mathbb{N}: x_i \neq n \rbrace \text{ is finite} \rbrace\]하지만 이제 다음의 문제가 생긴다. 다음 튜플은 $[0]$으로 간주해야 하는가, $[1]$로 간주해야 하는가?
\[(0, 1, 0, 1, 0, 1, \dots)\]이 모호함을 제거하기 위해 우리는 짝수 집합과 홀수 집합 중 하나를 임의로 채택할 것이다. 만약 짝수 집합을 채택했다면 위 튜플은 $[0]$이 되고(인덱스는 0부터 시작하는 것으로 전제한다) 홀수 집합을 채택했다면 $[1]$이 될 것이다.
하지만 이 채택의 과정에는 주의가 필요하다. 만약 6의 배수의 집합이 채택되었다면, 3의 배수의 집합 또한 채택되어야 논리적으로 일관된다. 후자를 만족하는 튜플은 자명하게 전자를 만족하기 때문이다. 그리고 3의 배수의 집합이 채택되었으므로, 3의 배수가 아닌 수의 집합은 기각되어야 한다. 자연수의 모든 부분집합에 대해 이같은 채택과 기각의 과정을 거친 결과물은 초필터ultrafilter라고 불리는 구조와 상응될 것이다. 적절한 초필터가 주어지면 그것을 토대로 임의의 튜플을 초자연수에 대응시킬 수 있으며, 이 전체적인 과정을 초곱ultraproduct이라고 부른다.
2. 초필터의 정의
정의. $X$가 집합이라고 하자. $X$의 부분집합들로 이루어진 집합 $\mathcal{F}$가 다음을 만족할 때, $X$의 필터라고 부른다.
- $X \in \mathcal{F}$
- $\varnothing \not\in \mathcal{F}$
- 상위집합 닫힘: $A \in \mathcal{F}, A \subset B \implies B \in \mathcal{F}$
- 유한 교집합 닫힘: $A, B \in \mathcal{F} \implies A \cap B \in \mathcal{F}$
직관적으로 필터는 “큰 집합들의 모임”이다. 이 관점에서 보면 1번과 2번 공리는 전체집합은 크고 공집합은 작다는 자명한 원리를 진술한다. 3번 공리는 큰 집합을 포함하는 집합은 크다는 원리를, 4번 공리는 큰 집합끼리 유한 번 교집합을 해도 여전히 크다는 원리를 진술한다.
여담으로 필터는 초곱뿐 아니라 퍼지 논리의 모형을 고전 논리의 모형으로 변환하는 데도 쓰인다. 이때 필터는 “큰 집합들의 모임”이 아닌 “참인 문장들의 모임”이 된다. 그리고 퍼지 논리에서 고전 논리로의 변환은 코헨의 강제법을 이해하는 한 가지 방식이기도 하다.
하세 다이어그램Hasse diagram을 통해 필터를 더 직관적으로 이해할 수 있다. 색칠된 영역은 $X = \lbrace 0, 1, 2 \rbrace$의 필터이다. 하세 다이어그램을 $\varnothing$에서 $X$로 가는 물줄기의 흐름으로 이해하면, 특정 지점에 잉크를 떨어뜨렸을 때 그 잉크가 퍼져 나가는 영역은 필터를 이룬다.
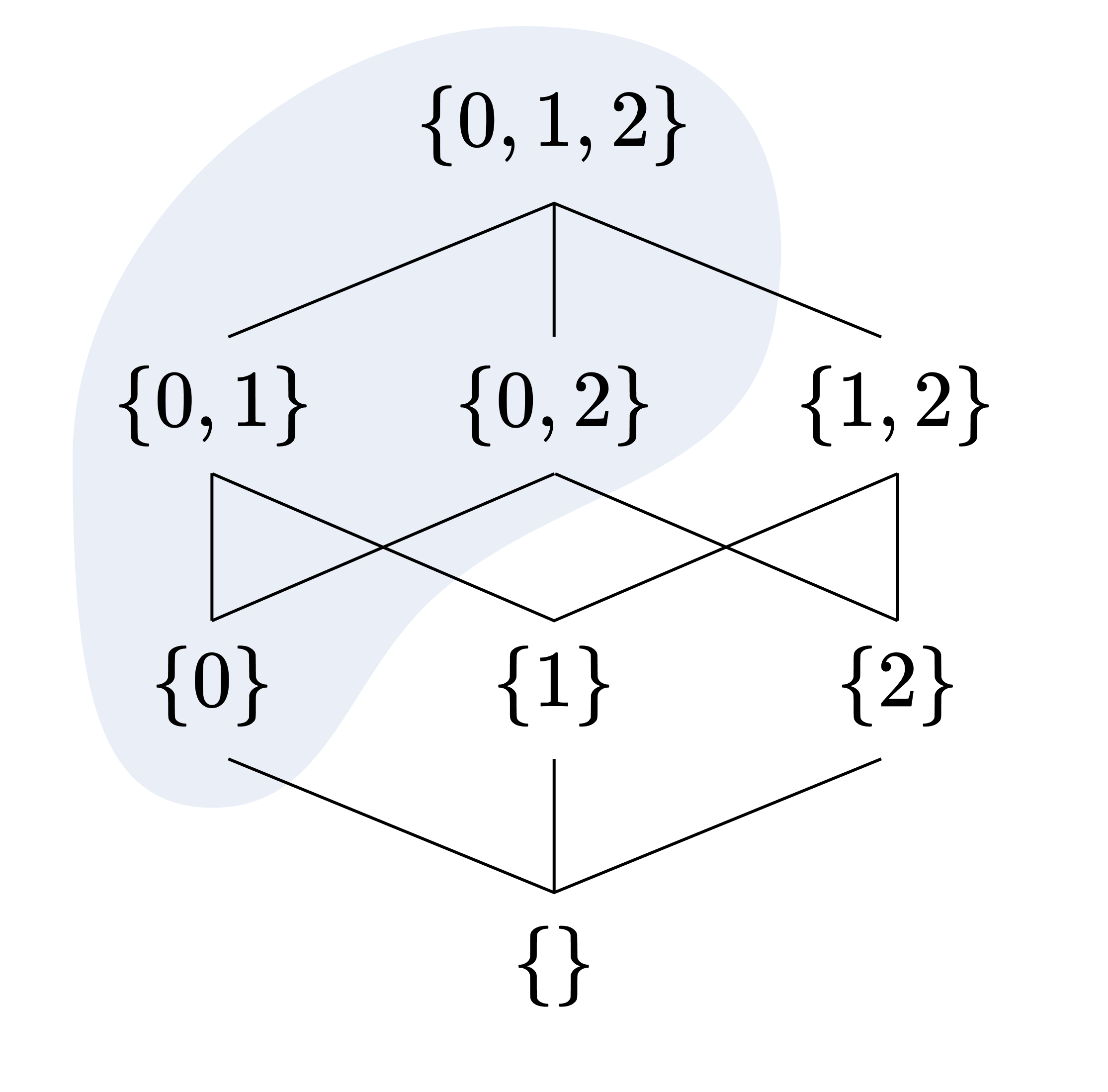
2번 공리와 4번 공리에 의해, $A \in \mathcal{F}$라면 $A^c := X \setminus A \notin \mathcal{F}$이다. 이 사실을 강화하여, $X$의 모든 부분집합에 대해 그 집합 또는 여집합이 필터에 있을 것을 요구하면 초필터의 정의를 얻는다.
정의. $X$의 필터 $\mathcal{F}$가 다음을 만족할 때 $\mathcal{F}$는 초필터이다.
\[\forall A \in \mathcal{P}(X) : A \in \mathcal{F} \lor A^c \in \mathcal{F}\]
앞선 그림의 필터는 초필터이다. 초필터는 하세 다이어그램의 정확히 절반을 차지한다는 사실에 주목하라.
3. 무한집합에서의 초필터
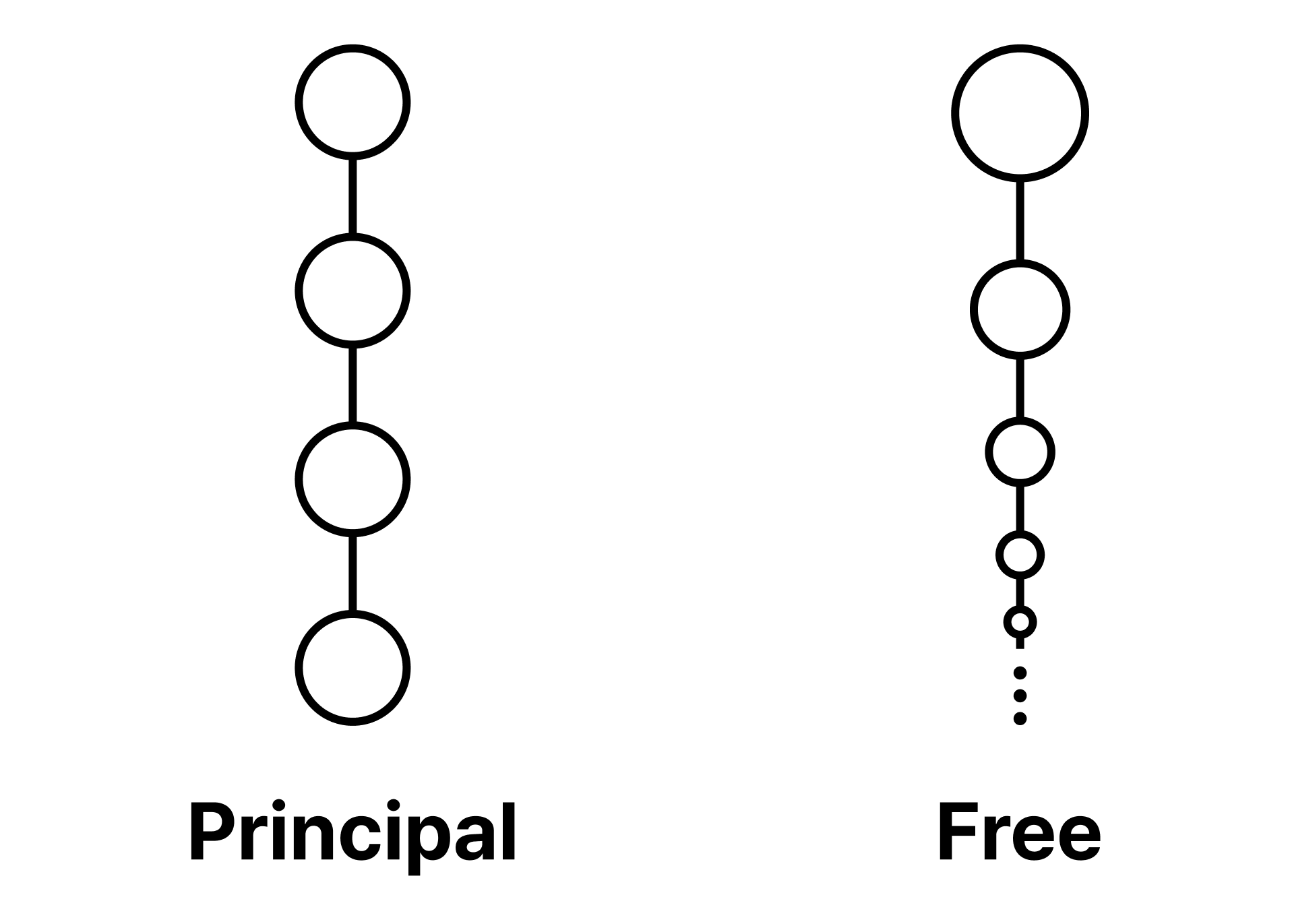
최소 원소를 가지는 필터를 주 필터principal filter라고 하며, 주 필터가 아닌 필터를 자유 필터free filter라고 한다. 지금까지 우리가 본 모든 필터는 주 필터로, “특정 지점에 떨어뜨린 잉크가 퍼져 나가는 영역”의 이미지와 완전히 부합한다.
연습문제. 모든 주 초필터는 홑원소 집합을 원소로 가짐을 보이시오.
주 필터와 달리 자유 필터는 직관적으로 포착하기 힘들다. 다음의 정리 때문이다.
정리. 유한집합 위의 필터는 모두 주 필터이다.
Proof. $A_0 \in \mathcal{F}$가 최소 원소가 아니라고 하자. 그러면 어떤 $B \in \mathcal{F}$가 존재하여 $A_1 = A_0 \cap B \subsetneq A$이다. 즉, $|A_1| < |A_0 |$이다. $A_1$이 최소 원소라면 증명이 끝나고, 아니라면 똑같은 과정을 반복한다. 주어진 집합의 크기가 유한하므로 이 과정은 계속 반복될 수 없으며, 최소 원소에 종착하게 된다. ■
위 정리는 이렇게 이해할 수도 있다. 자유 필터는 그 내부에 무한히 이어지지만 (따라서 유한 교집합만으로 최소 원소에 도달할 수 없다) 공집합에 도달하지는 않는 부분집합의 체인을 가지는 필터이다. 이에 따라 무한집합 위의 필터만이 자유 필터가 될 수 있다.
그 실례를 살펴보자.
정의. $X$가 무한집합이라고 하자. $A \subset X$가 여유한cofinite하다는 것은 $X \setminus A$가 유한집합인 것이다.
정리. $\mathbb{N}$의 모든 여유한 부분집합의 모임을 $\mathcal{F}$라고 하자. $\mathcal{F}$는 자유 필터이다.
증명은 연습문제로 남긴다. 위 정리의 $\mathcal{F}$를 프레셰 필터Fréchet filter라고 부른다. 일례로 10보다 큰 수들의 집합 $\lbrace 11, 12, 13, 14, \dots \rbrace$은 $\mathcal{F}$의 원소이지만, 짝수의 집합은 $\mathcal{F}$의 원소가 아니다.
프레셰 필터는 초필터가 아니다. 하지만 다음 정리에 의해 초필터로 확장할 수 있다.
정리. 모든 필터는 초필터로 확장될 수 있다.
Proof. $X$의 모든 필터들의 모임 $\Omega$에 포함 관계로 정의되는 순서를 주자. 이 순서 하에서 체인을 이루는 필터들의 합집합은 필터임을 어렵지 않게 보일 수 있다. 따라서 초른의 보조정리에 의해 $\Omega$는 극대 원소 $\mathcal{U}$를 가진다. 만약 $\mathcal{U}$가 초필터가 아니라면, 어떤 $A_0 \subset X$가 존재하여 $A_0, A_0^c \notin U$이다. 이제 다음과 같이 $\mathcal{V}$를 정의한다.
\[\mathcal{V} = \mathcal{U} \cup \lbrace A \subset X : A_0 \subset A \rbrace \cup \lbrace A_0 \cap U : U \in \mathcal{U} \rbrace\]$\mathcal{V}$는 필터임을 확인할 수 있다. 이것은 $\mathcal{U}$의 극대성에 위배된다. 따라서 $\mathcal{U}$는 초필터이다. ■
따라서 자연수 집합은 프레셰 필터로부터 확장되는 자유 초필터를 가진다. 이 필터를 프레셰 초필터라고 부르자.
4. 초자연수
지금까지의 논의를 정리하자면, 프레셰 초필터를 비롯한 자유 초필터는 다음의 성질을 가진다.
- 모든 여유한 집합을 원소로 가진다.
- 유한집합은 원소로 가지지 않는다.
- $A \subset \mathbb{N}$일 때 $A$가 필터의 원소이거나 $A^c$가 필터의 원소이다.
위 세 성질 덕분에 프레셰 초필터는 서론에서 초곱의 기초적인 아이디어를 개괄했을 때 맞닥뜨렸던 모호성의 문제를 해결하는 데 안성맞춤이다. 이제 우리는 다음과 같이 초자연수를 정의할 수 있다.
$\mathcal{U}$가 자유 초필터라고 하자. $\mathbb{N}^\omega$ 위에 다음의 동치 관계를 정의한다.
\[(n_0, n_1, n_2, \dots) \sim (m_0, m_1, m_2, \dots) \iff \lbrace i \in \mathbb{N} : n_i = m_i \rbrace \in \mathcal{U}\]이것이 동치 관계임은 어렵지 않게 확인할 수 있다. 따라서 다음과 같이 동치류를 취할 수 있다.
\[\mathbb{N}^* := \mathbb{N}^\omega/\sim\]$\mathbb{N}^*$을 초자연수라고 한다. 초자연수의 정의가 동치류인 것은 서론에서 초자연수를 $[n]$으로 적은 이유이다. 이제 남은 것은 초자연수의 연산과 술어 관계를 정의하는 것이다.
초자연수의 덧셈은 다음과 같이 자연스럽게 정의한다.
\[(n_0, n_1, \dots) + (m_0, m_1, \dots) = (n_0 + m_0, n_1 + m_1, \dots)\]여기에는 한 가지 미묘한 문제가 있다. 초자연수의 정의가 동치류이기 때문에, 동치류의 어떤 원소를 택하더라도 위 덧셈의 결과에 영향을 주지 않음을 보여야 한다. 즉,
\[\begin{gather} (n_0, n_1, \dots), (n_0', n_1', \dots) \in [n]\\ (m_0, m_1, \dots), (m_0', m_1', \dots) \in [m] \end{gather}\]에 대해,
\[(n_0, n_1, \dots) + (m_0, m_1, \dots), (n_0', n_1', \dots) + (m_0', m_1', \dots) \in [n + m]\]임을 보여야 한다. 다행히 이는 어렵지 않다.
곱셈과 역원 또한 비슷하게 정의하면 된다. 한편 $<$와 같은 이항 관계는 다음과 같이 정의한다.
\[(n_0, n_1, n_2, \dots) < (m_0, m_1, m_2, \dots) \iff \lbrace i \in \mathbb{N} : n_i < m_i \rbrace \in \mathcal{U}\]이 정의는 자연스럽게 삼항, 사항 관계로 일반화할 수 있다.
이로써 우리는 초자연수를 정의했다. 다음 글에서는 초자연수의 여러 비표준적인 특징과, 그런 비표준성에도 불구하고 초자연수와 자연수를 1차 논리로 구분할 수 없음을 보이는 워시의 정리를 살펴볼 것이다.
Fréchet Filters and Nonstandard Natural Numbers
22 Jan 2025Löwenheim-Skolem theorem states that there exist models that are elementarily equivalent yet nonisomorphic to the standard model of arithmetics. In other words, there exist number systems that satisfy all first-order sentences of arithmetics, yet are not “the” natural numbers.
In this article, we construct the hypernaturals, a representative nonstandard model of arithmetic, using ultraproducts, and prove Łoś’s theorem, which states that this model is elementarily equivalent to the standard model of arithmetics.
1. Overview
By the compactness theorem, we know that first-order logic cannot distinguish between the finite and the infinite. Therefore, we might reasonably expect to be able to define a model that is indistinguishable from the standard model with respect to every first-order formula by a clever use of infinity.
To this end, we may tro to define the hypernaturals $[0], [1], [2], \dots$ as follows:
\[\begin{aligned} [0] &= (0, 0, 0, 0, 0, \dots) \\ [1] &= (1, 1, 1, 1, 1, \dots) \\ [2] &= (2, 2, 2, 2, 2, \dots) \end{aligned}\]This definition makes sense, but upon reflection, requiring all entries to be 0 in order to regard it as $[0]$ is excessively stringent. For instance, it would be natural to regard the tuple $(1, 1, 0, 0, 0, \dots)$, where the only the first two entries are nonzero, as $[0]$ as well. Therefore, let us consider a tuple as $[n]$ if all but finitely many entries equal $n$. That is,
\[[n] = \lbrace (x_1, x_2, x_3, \dots) \in \mathbb{N}^\omega : \lbrace i \in \mathbb{N}: x_i \neq n \rbrace \text{ is finite} \rbrace\]However, this now gives rise to the following problem. Should the following tuple be considered as $[0]$ or as $[1]$?
\[(0, 1, 0, 1, 0, 1, \dots)\]To resolve this ambiguity, we shall arbitrarily choose one among the set of even numbers and the set of odd numbers. If we choose the even numbers, the above tuple becomes $[0]$ (indices begin at 0), while if we choose the odd numbers it becomes $[1]$.
This “choosing” requires some intricacy. For example, if the set of multiples of 6 is chosen, then the set of multiples of 3 must also be chosen for consistency, since tuples satisfying the latter trivially satisfy the former. Moreover, since the set of multiples of 3 is chosen, the set of numbers that are not multiples of 3 must be rejected. The end result of this process of choosing and rejecing for all subsets of the natural numbers will give rise to a structure called an ultrafilter. Given an appropriate ultrafilter, we can map any tuple to a hypernatural, and this entire process is called an ultraproduct.
2. Definition of Ultrafilters
Definition. Let $X$ be a set. A collection $\mathcal{F}$ of subsets of $X$ is called a filter on $X$ if it satisfies the following:
- $X \in \mathcal{F}$
- $\varnothing \not\in \mathcal{F}$
- Upward closure: $A \in \mathcal{F}, A \subset B \implies B \in \mathcal{F}$
- Finite intersection closure: $A, B \in \mathcal{F} \implies A \cap B \in \mathcal{F}$
Intuitively, a filter is a “collection of large sets”. From this perspective, axioms 1 and 2 express the trivial principle that the whole set is large and the empty set is small. Axiom 3 expresses the principle that a set containing a large set is large, while axiom 4 expresses the principle that finite intersections of large sets remain large.
As a side note, filters are used not only in ultraproducts but also in converting models of fuzzy logic into models of classical logic. In this context, filters become “collections of true statements” rather than “collections of large sets”. And indeed, the conversion from fuzzy logic to classical logic is also one way of understanding Cohen’s forcing method.
Filters can be understood more intuitively through Hasse diagrams. The shaded region represents a filter on $X = \lbrace 0, 1, 2 \rbrace$. If we understand the Hasse diagram as representing a stream of water from $\varnothing$ to $X$, the region an ink dropped at a particular point spreads over forms a filter.
By axioms 2 and 4, if $A \in \mathcal{F}$, then $A^c := X \setminus A \notin \mathcal{F}$. Strengthening this fact by requiring that for every subset of $X$, either the set or its complement is in the filter, we obtain the definition of an ultrafilter.
Definition. A filter $\mathcal{F}$ on $X$ is an ultrafilter if it satisfies:
\[\forall A \in \mathcal{P}(X) : A \in \mathcal{F} \lor A^c \in \mathcal{F}\]
The filter in the previous diagram is an ultrafilter. Note that an ultrafilter occupies exactly half of the Hasse diagram.
3. Ultrafilters on Infinite Sets
A filter with the least element is called a principal filter, while a filter that is not principal is called a free filter. All filters we have seen so far are principal filters, which perfectly match the image of “the region an ink dropped at a particular point spreads over”.
Exercise.
- Show that the least element of a principal filter is a singleton.
- Show that “a filter with a minimal element” is an equivalent definition of the principal filter.
Unlike principal filters, free filters are difficult to visualise intuitively, due to the following theorem:
Theorem. Every filter on a finite set is principal.
Proof. Suppose $A_0 \in \mathcal{F}$ is not a minimal element. Then there exists some $B \in \mathcal{F}$ such that $A_1 = A_0 \cap B \subsetneq A$. That is, $|A_1| < |A_0 |$. If $A_1$ is a minimal element, the proof is complete; otherwise, we repeat the same process. Since the given set has finite cardinality, this process cannot continue indefinitely and must terminate at a minimal element. ■
This theorem can also be understood as follows: a free filter is one that contains an infinitely descending chain of subsets within it. It thus does not reach a minimal element nor the empty set through finite intersections. Hence, only filters on infinite sets can be free.
Let us examine a concrete example.
Definition. Let $X$ be an infinite set. A subset $A \subset X$ is cofinite if $X \setminus A$ is finite.
Theorem. Let $\mathcal{F}$ be the collection of all cofinite subsets of $\mathbb{N}$. Then $\mathcal{F}$ is a free filter.
The proof is left as an exercise. The $\mathcal{F}$ in the above theorem is called the Fréchet filter. For instance, the set of numbers greater than 10 is an element of $\mathcal{F}$, but the set of even numbers is not.
Fréchet filter is not an ultrafilter. However, it can be extended to an ultrafilter by the following theorem:
Theorem. Every filter can be extended to an ultrafilter.
Proof. Let $\Omega$ be the collection of all filters on $X$, ordered by inclusion. Under this ordering, the union of filters forming a chain is itself a filter, as can be shown without much difficulty. Therefore, by Zorn’s lemma, $\Omega$ has a maximal element $\mathcal{U}$. We now claim that $\mathcal{U}$ is an ultrafilter. Assuming otherwise, there exists some $A_0 \subset X$ such that $A_0, A_0^c \notin U$. Define $\mathcal{V}$ as follows:
\[\mathcal{V} = \mathcal{U} \cup \lbrace A \subset X : A_0 \subset A \rbrace \cup \lbrace A_0 \cap U : U \in \mathcal{U} \rbrace\]One can verify that $\mathcal{V}$ is a filter. This contradicts the maximality of $\mathcal{U}$. Therefore, $\mathcal{U}$ is an ultrafilter. ■
Hence, the set of natural numbers possesses a free ultrafilter extending from the Fréchet filter. Let us call this filter the Fréchet ultrafilter.
4. The Hypernaturals
To summarise our discussion thus far, free ultrafilters, including the Fréchet ultrafilter, possess the following properties:
- They contain all cofinite sets as elements.
- They do not contain finite sets as elements.
- For $A \subset \mathbb{N}$, either $A$ is an element of the filter or $A^c$ is an element of the filter.
These three properties make the Fréchet ultrafilter perfectly suited for resolving the ambiguity problem we encountered when outlining the basic idea of ultraproducts in the introduction. We can now define the hypernaturals as follows.
Let $\mathcal{U}$ be a free ultrafilter. Define the following equivalence relation on $\mathbb{N}^\omega$:
\[(n_0, n_1, n_2, \dots) \sim (m_0, m_1, m_2, \dots) \iff \lbrace i \in \mathbb{N} : n_i = m_i \rbrace \in \mathcal{U}\]It is not difficult to verify that this is indeed an equivalence relation. Therefore, we can take equivalence classes:
\[\mathbb{N}^* := \mathbb{N}^\omega/\sim\]We call $\mathbb{N}^*$ the hypernaturals. This reveals why the hypernaturals were written as $[n]$ in the introduction — a hypernatural number is an equivalence class. Indeed, it would have more accurate to write $[n]$ ans $[(n, n, n, \dots)]$, but let us allow ourselves some abuse of notation.
What remains now is to define operations and relations on the hypernaturals. Addition of hypernaturals is defined naturally as follows:
\[[(n_0, n_1, \dots)] + [(m_0, m_1, \dots)] = [(n_0 + m_0, n_1 + m_1, \dots)]\]There is one subtle issue here. Since hypernaturals are equivalence classes, we need to show that the above operation is well-defined regardless of which representative of an equivalence class we choose. That is, for
\[\begin{gather} (n_0, n_1, \dots), (n_0', n_1', \dots) \in [n]\\ (m_0, m_1, \dots), (m_0', m_1', \dots) \in [m], \end{gather}\]we need to show that
\[(n_0, n_1, \dots) + (m_0, m_1, \dots), (n_0', n_1', \dots) + (m_0', m_1', \dots) \in [n + m]\]Fortunately, this is not too difficult to establish and is left as an exercise.
Multiplication and successor can be defined similarly. Binary relations such as $<$ are defined as follows:
\[(n_0, n_1, n_2, \dots) < (m_0, m_1, m_2, \dots) \iff \lbrace i \in \mathbb{N} : n_i < m_i \rbrace \in \mathcal{U}\]This definition can be naturally generalised to ternary and quaternary relations.
We have thus defined the hypernaturals. In the next article, we shall examine various nonstandard features of the hypernaturals and Łoś’s theorem, which shows that despite such nonstandardness, the hypernaturals and natural numbers cannot be distinguished by first-order logic.
지시에 대하여 — 한정 기술구
18 Jan 20254. 한정 기술구
이름과 달리 한정 기술구와 관련하여 제기되는 일차적인 질문은 과연 한정 기술구는 지시를 하느냐는 것이다. 프레게는 한정 기술구 또한 이름과 마찬가지로 뜻(한정 기술구의 내용)과 지시체(해당 내용을 유일하게 만족하는 대상)를 가진다고 봤지만, 러셀은 한정 기술구가 지시체를 가지지 않는다고 보았다.
4.1. 러셀의 기술주의
러셀의 주장
러셀에 따르면 한정 기술구는 대상을 지시하지 않는다. 오히려 한정 기술구는 2차 술어와 의미론적으로 동등하다. 요컨데 술어 P를
P: 대상 → 진릿값
와 같은 함수로 생각할 수 있듯이, D가 한정 기술구일 때
D: (대상 → 진릿값) → 진릿값 (i.e. 술어 → 진릿값)
이다. 이 관점에 따르면 “현재 영국의 왕”은 찰스 3세를 지시하는 것이 아닌, ”x는 남자이다”, “x는 영국인이다”, “x는 엘리자베스 2세의 아들이다” 등에 대해서는 참을 반환하고, “x는 여자이다”, “x는 미국인이다”, “x는 제임스 1세의 아들이다”에 대해서는 거짓을 반환하는 2차 술어이다.
러셀의 기술주의의 강점은 “현재 프랑스의 왕은 대머리이다“와 같이 지시체를 결여하는 한정 기술구가 어떻게 유의미한 문장에서 쓰일 수 있는지(프레게에 따르면 이 문장은 무의미하지만 러셀에 따르면 이 문장은 그저 거짓이다), 그리고 프레게의 퍼즐을 설명할 수 있다는 것이다.
나아가 러셀은 ‘이것’과 ‘나’를 제외한 모든 이름이 위장된 한정 기술구라고 주장한다. 이 주장은 언어의 의미론을 단순명료하게 만드는 장점이 있지만 크립키의 양상 및 의미론적 논증을 잘 설명하지 못한다. 따라서 이 글에서는 “한정 기술구는 지시하지 않는다”라는 러셀의 주장만 살펴 보기로 한다.
Remark. 하지만 러셀의 기술주의가 정말로 프레게의 퍼즐을 설명하는가에 대해서는 의문의 여지가 있다. 술어에 대한 외연적 정의를 택할 경우, ’샛별‘과 ’개밥바라기‘는 정확히 같은 (2차) 술어가 되기 때문이다. 내포주의와 외연주의에 대한 콰인 등의 논변도 참고할 만하다.
스트로슨의 이론
다음 문장을 보자.
그 책상은 책에 덮여 있다. (The table is covered with books.)
이 문장은, 예컨데 화자가 방에 있고, 방에 책상이 딱 하나 있으며, 그 책상이 책에 덮여 있을 때 참인 듯하다. 그러나 러셀의 기술주의에 따르면 이 우주에는 책상이 하나보다 많으므로 문장은 거짓이다.
이에 대해 스트로슨은 한정 기술구가 진정으로 지시를 하는 경우가 있다고 주장한다. 한정 기술구가 지시적 사용으로 사용되면, 한정 기술구는 기술의 내용을 만족하는 대상 중 해당 맥락에서 가장 두드러지는 대상을 지시한다. 반면 한정 기술구가 속성적 사용으로 사용될 때 기술구는 러셀의 이론처럼 작동한다.
도넬란의 이론
다음 문장을 보자.
마티니를 마시는 그 남자는 누구인가? (Who is the man drinking a martini?)
이 문장의 화자가 지시하려고 하는 남자가 사실은 마티니가 아닌 물을 마시고 있었다고 하자. 이 경우 스트로슨에 따르면 “the man drinking a martini”는 지시적으로 사용될 수 없으며(해당 맥락에서 마티니를 마시고 있는 남자가 없으므로), 속성적으로 사용될 수도 없다(전 세계에서 현재 마티니를 마시고 있는 남자가 여러 명이므로).
따라서 도넬란은 한정 기술구가 그 기술적 내용을 만족하지 않는 대상 또한 지시할 수 있다고 주장한다. 중요한 것은 화자가 한정 기술구로써 특정 대상을 지칭하려는 의도이다. 도넬란의 이론은 한정 기술구에 대한 험티덤티 문제로 빠지는 듯하며, 이를 의식한 도넬란은 그라이스식 의미 이론에 호소한다.
크립키의 이론
크립키는 우리가 “마티니를 마시는 그 남자는 누구인가?”와 같은 문장을 화용론적으로 이해하면 그 어떤 경우에도 한정 기술구는 지시하지 않는다는 강한 러셀주의를 견지할 수 있다고 주장한다.
크립키는 지시가 순전히 규약(convention — 알고리즘으로 이해하는 것이 더 적절할 수 있다)으로 이루어져야 한다고 보는 듯하다. 일례로 크립키의 이름 이론은 이름 $N$이 주어졌을 때, 이 이름이 지칭하는 대상이 인과 이론으로 정확하게 특정된다. 그러나 이름에 대한 강한 규약주의가 다수의 담지자를 가지는 이름이나 불순 지표사의 원리를 제대로 설명하지 못한다는 점을 보았을 때 크립키의 규약주의는 근거가 미약하며, 이에 따라 도넬란주의를 거부하는 크립키의 주장 또한 근거가 미약하다.
한정 기술구 v. 비한정 기술구
최근에는 한정 기술구(the F)와 비한정 기술구(a F)의 구분 자체가 의문시되고 있다. 둘의 차이를 정확하게 정의하기가 매우 까다로운 일로 드러났을 뿐더러, 둘을 문법적으로 구분하지 언어가 수많이 보고되었기 때문이다. 만약 한정 기술구와 비한정 기술구의 구분이 부당한 것으로 드러난다면, 이것은 한정 기술구가 지시를 하지 않는다는 러셀주의를 보강할 수 있을 것이다. (또는, 비한정 기술구 또한 지시를 한다는 매우 논란적인 주장을 개진해야 할 것이다)
5. 지시 회의주의
기술주의, 밀주의, 그리고 지표사 이론들은 지시가 철학적으로 탐구할 만한 주제이며 이에 대한 의미 있는 분석이 가능하다는 입장에서 일치한다. 그러나 지시가 본질적으로 무의미하거나 공허한 개념이라고 주장하는, 이른바 “지시 회의주의적” 입장들도 존재한다.
콰인의 회의주의
콰인은 번역 불확정성 논제를 통해 ‘가바가이’와 같은 지시 표현들이 불가해하다고 주장한다. 번역 불확정성 논제에 대해서는 필자가 이전에 쓴 바가 있으니 그쪽을 참고.
다수의 문제
다수의 문제는 지시 표현이 지시하는 대상의 경계를 어떻게 정의해야 하는가에 대한 문제이다. 예를 들어 나는 ‘경복궁’으로 현재의 경복궁을 지시할 수 있다. 그런데 어느 날 경복궁의 기와가 불타 없어지는 사건이 일어났다고 상상해 보자. 화재 사건 이후에도 나는 ’경복궁‘으로 (이제는 기와가 없는) 경복궁을 지시할 수 있는 듯하다. 그렇다면 화재 사건 이전과 이후의 ‘경복궁’은 동일한 지시체를 가진다고 말할 수 있는가? 경복궁이 얼마나 불타 없어져야 더이상 그것은 ‘경복궁’의 지시체가 될 수 없는가? 이 문제는 지시 표현이 지시체를 가진다는 일반적인 도식에 의혹을 제기한다.
데이비드슨의 참 이론
철학자들이 지시에 대한 이론을 추구하는 이유는 그것이 언어의 의미론을 세우는 데 필요하기 때문이다. 즉, 문장에 등장하는 각 표현의 지시체가 결정되어야 해당 문장의 진릿값을 결정할 수 있다.
그러나 데이비드슨은 이것이 본말을 전도하는 것이라고 주장한다. 데이비드슨은 문장에 대한 참 이론을 제시하는 것만으로 해당 언어의 의미론을 세울 수 있고, 이에 따라 지시 이론은 불필요하다고 주장한다. 참에 대한 철학적 논의는 이후 별개의 시리즈로 정리하도록 하겠다.
On Reference — Definite Descriptions
18 Jan 2025This post was originally written in Korean, and has been machine translated into English. It may contain minor errors or unnatural expressions. Proofreading will be done in the near future.
4. Definite Descriptions
Unlike names, the primary question raised concerning definite descriptions is whether definite descriptions actually refer. Frege held that definite descriptions, like names, possess both sense (the content of the definite description) and reference (the object that uniquely satisfies that content), while Russell maintained that definite descriptions do not have referents.
4.1. Russell’s Theory of Descriptions
Russell’s Claim
According to Russell, definite descriptions do not refer to objects. Rather, definite descriptions are semantically equivalent to second-order predicates. In other words, just as we can think of a predicate P as
P: object → truth value
when D is a definite description, we have
D: (object → truth value) → truth value (i.e. predicate → truth value)
According to this view, “the present King of Britain” does not refer to Charles III, but rather is a second-order predicate that returns true for “x is male”, “x is British”, “x is the son of Elizabeth II”, etc., and returns false for “x is female”, “x is American”, “x is the son of James I”, etc.
The strength of Russell’s theory of descriptions lies in its ability to explain how definite descriptions lacking referents can be used meaningfully in sentences such as “The present King of France is bald” (according to Frege this sentence would be meaningless, but according to Russell this sentence is simply false), and to resolve Frege’s puzzle.
Furthermore, Russell claims that all names except ‘this’ and ‘I’ are disguised definite descriptions. while this claim has the advantage of making the semantics of language elegantly simple, it fails to adequately explain Kripke’s modal and semantic arguments. Therefore, this essay shall examine only Russell’s claim that “definite descriptions do not refer”.
Remark. However, there remains doubt as to whether Russell’s theory of descriptions truly resolves Frege’s puzzle. If we adopt an extensional definition for predicates, then ‘the morning star’ and ‘the evening star’ become exactly the same (second-order) predicate. The arguments of Quine and others regarding intensionalism and extensionalism are also worth considering.
Strawson’s Theory
Consider the following sentence:
The table is covered with books.
This sentence appears to be true when, for instance, the speaker is in a room, there is exactly one table in the room, and that table is covered with books. However, according to Russell’s theory of descriptions, since there is more than one table in the universe, the sentence is false.
In response, Strawson argues that there are cases where definite descriptions genuinely refer. When a definite description is used referentially, the definite description refers to the object amongst those satisfying the descriptive content that is most salient in the given context. Conversely, when a definite description is used attributively, the description functions as in Russell’s theory.
Donnellan’s Theory
Consider the following sentence:
Who is the man drinking a martini?
Suppose that the man the speaker intends to refer to is actually drinking water, not a martini. In this case, according to Strawson, “the man drinking a martini” cannot be used referentially (since there is no man drinking a martini in the relevant context), nor can it be used attributively (since there are multiple men currently drinking martinis worldwide).
Therefore, Donnellan argues that definite descriptions can also refer to objects that do not satisfy their descriptive content. What matters is the speaker’s intention to designate a particular object with the definite description. Donnellan’s theory appears to fall into the problem of rigidity concerning definite descriptions, and being conscious of this, Donnellan appeals to Gricean theories of meaning.
Kripke’s Theory
Kripke argues that if we understand sentences such as “Who is the man drinking a martini?” pragmatically, we can maintain a strong Russellian position that definite descriptions never refer under any circumstances.
Kripke appears to hold that reference must be achieved purely through convention (though it might be more appropriate to understand this as an algorithm). For instance, Kripke’s theory of names precisely specifies, given a name $N$, the object that this name designates through causal theory. However, given that strong conventionalism about names fails to properly explain names with multiple bearers or the principle of impure indexicals, Kripke’s conventionalism lacks solid foundation, and consequently Kripke’s argument against Donnellanism is also weakly grounded.
Definite Descriptions v. Indefinite Descriptions
Recently, the very distinction between definite descriptions (the F) and indefinite descriptions (a F) has come under question. Not only has precisely defining the difference between them proved to be extremely challenging, but numerous languages have been reported that do not grammatically distinguish between the two. If the distinction between definite and indefinite descriptions proves to be unfounded, this could strengthen Russellian views that definite descriptions do not refer. (Alternatively, one would have to advance the highly controversial claim that indefinite descriptions also refer.)
5. Referential Scepticism
Descriptivism, Millianism, and indexical theories agree in their position that reference is a philosophically worthy subject of enquiry and that meaningful analysis thereof is possible. However, there also exist so-called “referentially sceptical” positions that argue reference is an essentially meaningless or vacuous concept.
Quinean Scepticism
Quine argues through the indeterminacy of translation thesis that referential expressions such as ‘gavagai’ are incomprehensible. Regarding the indeterminacy of translation thesis, the present author has written previously, which may be consulted.
The Problem of the Many
The problem of the many concerns how to define the boundaries of the object that a referential expression refers to. For example, I can refer to the present Gyeongbokgung Palace with ‘Gyeongbokgung’. Now imagine that one day an incident occurs in which the roof tiles of Gyeongbokgung are burnt away. Even after the fire incident, it seems I can still refer to Gyeongbokgung (now without roof tiles) with ‘Gyeongbokgung’. Can we then say that ‘Gyeongbokgung’ before and after the fire incident has the same referent? How much of Gyeongbokgung must be burnt away before it can no longer be the referent of ‘Gyeongbokgung’? This problem raises doubts about the general schema that referential expressions have referents.
Davidson’s Theory of Truth
The reason philosophers pursue theories of reference is that they are necessary for establishing the semantics of language. That is, the referent of each expression appearing in a sentence must be determined in order to determine the truth value of that sentence.
However, Davidson argues that this puts the cart before the horse. Davidson claims that merely providing a theory of truth for sentences suffices to establish the semantics of the relevant language, and that reference theory is therefore unnecessary. Philosophical discussions of truth shall be organised in a separate series hereafter.
지시에 대하여 — 특성 모델과 의도주의
13 Jan 20253. 지표사
지표사란 ‘나’, ‘너’, ’여기‘, ’지금‘, ’그‘, ’이것‘, ’저것‘과 같은 표현을 일컫는다. 지표사는 ’나‘, ’너‘, ’여기‘, ’지금‘과 같이 맥락이 주어졌을 때 지시체가 비교적 분명한 순수 지표사와 ’그’, ‘이것’, ’저것’과 같이 지시체가 비교적 불분명한 불순 지표사로 구분하는 것이 일반적이나, 모든 학자가 이 구분을 유의미하게 받아들이는 것은 아니다.
3.1. 순수 지표사
3.1.1. 기술주의는 순수 지표사를 적절히 설명하는가?
일면 기술주의는 ‘나’의 지시체가 “이 발화의 화자”라는 기술적 내용을 통해 결정된다고 주장함으로써 순수 지표사를 적절히 설명하는 것으로 보인다. 그런데 여기에는 두 가지 문제가 있다.
첫째, “이 발화의 화자”가 기술구에 해당하는지 불분명하다. 보통 기술구는 순전히 그 내용만으로 해당하는 대상을 특정해 내며, 그렇기에 기술(description)이라고 불린다. 그런 점에서 “이 발화의 화자”는 일반적인 기술구로 보기에 문제가 있다.
일례로 어느 날 침대에서 일어난 당신 앞에 다음과 같은 쪽지가 있었다고 하자.
브렉시트를 시행한 영국의 전 총리 는 누구인가?
그럼 당신은 — 혼란스럽기야 하겠지만 — ‘보리스 존슨’이라고 답할 것이다. 그러나 쪽지에 적힌 질문이 다음과 같았다면 어떨까?
이 문장의 화자 는 누구인가?
위 쪽지만 가지고서는 이 문장의 화자 가 지시하는 바를 알 수 없다. 즉, 이 문장의 화자 는 의미론적 계층을 넘어, 언어의 구체적인 사용과 관련된 화용론적 계층에 호소한다.
이와 연관된 두 번째 문제는, “이 발화의 화자”가 ‘나’의 의미일 경우 ‘나’의 사용과 관련하여 이상한 예측을 내놓는다는 점이다. 일례로 앨리스와 밥이 ”나는 배고프다“라고 발화한 경우, 앨리스와 밥은 서로 다른 바를 주장했다고 보는 편이 자연스럽다. 그러나 기술주의는 앨리스와 밥이 둘 다 ”이 발화의 화자는 배고프다“라는 동등한 내용을 주장했다는 예측을 내놓는다.
3.1.2. 라이헨바흐의 해결법: 사례 재귀성
라이헨바흐는 지표사가 사례 재귀적(token reflexive)이라고 주장함으로써 기술주의와 지표사 사이의 간극을 메꾸고자 했다. 즉, 앨리스가 2025년 1월 13일 오후 4시 53분 광화문에서 ”나는 배고프다“라고 발화했다면 이 문장에서 ‘나’와 결부되는 기술구는 2025년 1월 13일 오후 4시 53분 광화문에서 “나는 배고프다”라고 발화한 화자 이다.
3.1.3. 캐플런의 해결법: 특성 모델
캐플런은 라이헨바흐의 접근법을 밀주의적으로 변형시켰다. 캐플런은 두 가지 유형의 의미를 구분한다. 내용(content)는 우리가 지금까지 의미라고 불렀던 것으로, 밀주의자 캐플런에게 있어 이름의 내용은 그 지시체이다. 한편 특성(character)은 사용 규칙으로서, 주어진 맥락에서 표현의 내용이 무엇인지 결정한다.
캐플런은 엄격한 의미에서 동명인 이인이 존재하지 않는다는 입장이기 때문에 그에 따르면 이름은 불변 특성(constant character)을 가진다. 예를 들어 ‘보리스 존슨ᵢ ’의 내용은 모든 맥락에서 보리스 존슨ᵢ을 지시체로 산출하라 이다.
반면 순수 지표사의 특성은 이 화자를 산출하라, 이 발화의 위치를 산출하라 등과 같다. 캐플런의 입장을 받아들이면 우리는 ”나는 지금 여기에 있다“가 어떻게 논리적으로는 필연적이지만(’나‘, ’지금‘, ’여기‘의 특성은 이 문장이 모든 맥락에서 참임을 보장한다) 형이상학적으로는 필연적이지 않은지(주어진 맥락에서 ’나‘, ’지금‘, ’여기‘를 그 내용으로 대치한 문장은 필연적으로 참이 아니다) 설명할 수 있으며, 앨리스와 밥의 사례 또한 해결한다.
Remark. 캐플런의 이론에 대한 유명한 반박으로 자동응답기 역설을 찾아보라.
3.1.4. 인과 이론과 특성 모델의 융합
인과 이론과 특성 모델은 밀주의 이론이라는 공통점을 갖기에 둘을 융합하여 이름에 대한 보다 정교한 이론을 제시할 수 있다.
앞서 말했듯이 캐플런은 (1) 이름을 심적 현상으로 간주하며, (2) 이에 따라 다수의 담지자를 가지는 이름은 존재하지 않으므로 (3) 이름의 특성은 불변이라고 주장했다. 그러나 이름을 심리 현상으로 보는 입장은 다소 부담스럽다. 대신 (1), (2), (3)을 다음과 같이 수정해 봄직하다.
- 이름은 언어적 현상이다.
- 다수의 담지자를 가지는 이름이 존재한다.
- 이름의 특성은 그 이름의 담지자 집합 중, 현 맥락에서 가장 두드러지는(most salient) 대상을 지시체로 산출하는 것이다.
여기에 더불어 인과 이론적인 4번 논제를 추가한다.
- 이름의 담지자 집합은 그 이름가 결부되는 인과적 사슬 중 최초로 명명된 대상들의 집합이다.
이같은 인과 이론과 특성 모델의 융합은 매력적이지만 한계가 없는 것은 아니다. 특히, 인과 이론의 강점인 “이름의 전달만으로 피전달자가 이름으로 지시할 수 있게 되는 원리”를 완벽히 보존하지 못한다. (필자왈: 뭐 그렇다고 한다 내가 보기에 이 이론은 완벽한 거 같은데~)
3.2. 불순 지표사
‘그’, ‘그녀’와 같은 불순 지표사, 또는 ‘이것’, ‘저것’과 같은 ‘진정한 지표사’의 의미는 순수 지표사보다 더 불분명하다. 웨트스타인과 앨리슨 마운트는 불순 지표사가 지시하는 대상은 해당 맥락에서 가장 두드러지는 인물/대상이라는 노선의 이론을 발전시켰다.
그렇다면 무엇이 특정 대상을 ‘해당 맥락에서 가장 두드러지는 대상’으로 만드는가? 아무래도 화자 또는 청자의 관심이라고 보는 편이 가장 자연스럽다. 하지만 누구의 편을 들어줘야 할까?
1. 마운트: 상호 두드러짐의 원리
주장. 마운트는 불순 지표사가 대상 $c$를 지시할 필요충분조건은 화자와 청자의 관심이 일치하며 둘에게 공통적으로 두드러지는 대상이 A인 것이라고 주장한다.
문제. 이 견해는 화자와 청자의 관심이 갈라지는 경우, 또는 청자가 우연히 화자의 말에 집중하지 않고 있었을 경우 지표사의 지시는 실패한다는 반직관적인 결론을 함의한다.
2. 캐플런: 의도주의
주장. 캐플런은 불순 지표사가 대상 $c$를 지시할 필요충분조건은 화자가 $c$을 지시하고자 하는 겨냥 의도로 지표사를 사용하는 것이라고 주장한다.
문제. 화자의 겨냥 의도가 무한히 유연할 수 있는 경우 험티덤티 문제가 발생한다. 예컨데 화자가 충분한 의도를 가지고 있는 한 화자는 도널드 트럼프의 사진을 가리키며 루돌프 카르납을 지시할 수 있게 되는데, 이것은 매우 반직관적이다.
또한 캐플런은 다음의 복잡한 험티덤티 사례를 제시한다.
한 철학 교사는 교탁 뒤에 루돌프 카르납의 사진을 걸어 두었다. 그런데 어느 날 장난꾸러기 학생이 교사 몰래 카르납의 사진을 도널드 트럼프의 사진으로 바꿨다. 이 사실을 눈치채지 못한 교사는 학생들이 교실로 들어오자 자신의 등 뒤를 가리키며 ”저것은 20세기 가장 위대한 철학자 중 한 명이다“라고 말했다.
위 사례에서 교사는 ‘저것’이라는 지표사로 루돌프 카르납의 사진을 지시하고자 하는 의도를 가지고 있으나, 청자인 학생들은 이 의도를 잡아낼 수 없다. 그렇다면 여기서 의문이 든다. 교사의 발화는 참인가 거짓인가?
강한 의도주의에 따르면 교사가 카르납을 지시하려는 의도를 가지고 ‘저것’이라고 발화했으므로 ‘저것’은 카르납을 지시하며, 따라서 교사의 발화는 참이다.
3. 그라이스식 의도주의
게일 스타인은 그라이스의 의미론을 의도주의에 접목시켜 캐플런의 딜레마에 대한 다른 해답을 제공한다. 지표사 $i$가 대상 $c$를 지시하는 데 성공하기 위해서 화자는 세 가지 의도를 가져야 한다. 화자는 1) $i$로 $c$를 지시하려는 의도를 가져야 하고, 2) $i$로 청자에게 $c$를 지시체로 식별시키려는 의도를 가져야 하고, 3) 자신의 의도를 청자가 인식함으로써 청자에게 $c$를 지시치로 식별시키려는 의도를 가져야 한다.
그라이스식 의도주의는 험티덤티 문제를 해소한다. 캐플런의 험티덤티 문제를 해소하기 위해 스타인은 직접 지시와 간접 지시의 구분을 제시한다. 캐플런의 사례의 경우, 교사는 루돌프 카르납을 지시하려는 의도를 가지고 있으나 이 의도는 자신의 뒤에 있는 그림을 지시하려는 의도를 통해 이루어진다. 따라서 전자는 간접적 지시, 후자가 직접적 지시이다. 스타인은 간접적 지시체 직접적 지시체가 충돌할 경우 직접적 지시체가 우선권을 가진다고 주장한다. 즉, 교사의 발언은 거짓이다.
4. 라이머식 의도주의
그라이스식 의도주의는 ’상대가 내 마음을 읽을 수 있다고 믿는 화자‘의 경우와 같이 충분히 이상한 믿음을 가진 화자의 경우 험티덤티 문제를 제거하지 못한다는 한계(?)를 가진다.
이에 대해 라이머는 의도주의에 제약을 가하기 위한 다른 전략을 택하는데, 그의 전략은 제스처 우선순위로 요약할 수 있다. 라이머의 제약된 의도주의는 기대 이상으로 많은 험티덤티 문제를 명쾌하게 해결하는 것으로 보인다.
On Reference — Character Model and Intentionalism
13 Jan 2025This post was originally written in Korean, and has been machine translated into English. It may contain minor errors or unnatural expressions. Proofreading will be done in the near future.
3. Indexicals
Indexicals refer to expressions such as ‘I’, ‘you’, ‘here’, ‘now’, ‘he’, ‘this’, and ‘that’. It is common to distinguish between pure indexicals like ‘I’, ‘you’, ‘here’, and ‘now’, whose referents are relatively clear when context is given, and impure indexicals like ‘he’, ‘this’, and ‘that’, whose referents are relatively unclear. However, not all scholars accept this distinction as meaningful.
3.1. Pure Indexicals
3.1.1. Does Descriptivism Adequately Explain Pure Indexicals?
At first glance, descriptivism appears to adequately explain pure indexicals by claiming that the referent of ‘I’ is determined through the descriptive content “the speaker of this utterance”. However, there are two problems with this approach.
Firstly, it is unclear whether “the speaker of this utterance” constitutes a description. Typically, descriptions specify their corresponding objects purely through their content, and are thus called descriptions. In this respect, “the speaker of this utterance” is problematic as a general description.
For instance, suppose you wake up one day to find the following note in front of you:
Who is the former British Prime Minister who implemented Brexit?
You would answer ‘Boris Johnson’, albeit with some confusion. However, what if the question on the note were:
Who is the speaker of this sentence?
With only this note, one cannot determine what the speaker of this sentence refers to. That is, the speaker of this sentence appeals beyond the semantic level to the pragmatic level concerning the concrete use of language.
The second problem related to this is that if “the speaker of this utterance” is the meaning of ‘I’, it makes strange predictions regarding the use of ‘I’. For instance, when Alice and Bob both utter “I am hungry”, it seems natural to view them as making different claims. However, descriptivism predicts that Alice and Bob both made equivalent claims: “the speaker of this utterance is hungry”.
3.1.2. Reichenbach’s Solution: Token Reflexivity
Reichenbach attempted to bridge the gap between descriptivism and indexicals by claiming that indexicals are token reflexive. That is, if Alice uttered “I am hungry” at Gwanghwamun at 4:53 PM on 13th January 2025, then the description associated with ‘I’ in this sentence is the speaker who uttered “I am hungry” at Gwanghwamun at 4:53 PM on 13th January 2025.
3.1.3. Kaplan’s Solution: Character Models
Kaplan modified Reichenbach’s approach in a Millian direction. Kaplan distinguishes between two types of meaning. Content is what we have hitherto called meaning; for the Millian Kaplan, the content of a name is its referent. Meanwhile, character is a rule of use that determines what the content of an expression is in a given context.
Since Kaplan holds that there are no co-referential names in the strict sense, names have constant character according to him. For example, the content of ‘Boris Johnsonᵢ’ is produce Boris Johnsonᵢ as referent in all contexts.
In contrast, the character of pure indexicals is produce this speaker, produce the location of this utterance, and so forth. If we accept Kaplan’s position, we can explain how “I am here now” is logically necessary (the character of ‘I’, ‘now’, and ‘here’ ensures that this sentence is true in all contexts) but not metaphysically necessary (the sentence obtained by substituting ‘I’, ‘now’, and ‘here’ with their content in a given context is not necessarily true), and also resolve the case of Alice and Bob.
Remark. For a famous objection to Kaplan’s theory, see the answering machine paradox.
3.1.4. Fusion of Causal Theory and Character Models
Since both causal theory and character models are Millian theories, they can be fused to present a more sophisticated theory of names.
As mentioned earlier, Kaplan claimed that (1) names are mental phenomena, (2) accordingly, names with multiple bearers do not exist, and therefore (3) the character of names is constant. However, viewing names as psychological phenomena is somewhat burdensome. Instead, we might modify (1), (2), and (3) as follows:
- Names are linguistic phenomena.
- Names with multiple bearers exist.
- The character of a name produces as referent the most salient object in the current context from the set of that name’s bearers.
In addition to this, we add a fourth thesis from causal theory:
- The set of bearers of a name is the set of objects initially named in the causal chains associated with that name.
Such a fusion of causal theory and character models is attractive but not without limitations. In particular, it does not perfectly preserve the strength of causal theory: “the principle by which the mere transmission of a name enables the recipient to refer with that name”. (Author’s note: Well, so they say, but this theory seems perfect to me~)
3.2. Impure Indexicals
The meaning of impure indexicals such as ‘he’ and ‘she’, or ‘genuine indexicals’ such as ‘this’ and ‘that’, is more unclear than that of pure indexicals. Wettstein and Alison Mount developed theories along the lines that impure indexicals refer to the most salient person/object in the relevant context.
What then makes a particular object ‘the most salient object in the relevant context’? It seems most natural to view it as the interest of the speaker or hearer. But whose side should we take?
1. Mount: Principle of Mutual Salience
Claim. Mount argues that the necessary and sufficient condition for an impure indexical to refer to object $c$ is that the interests of speaker and hearer coincide and that the object commonly salient to both is A.
Problem. This view implies the counterintuitive conclusion that when the interests of speaker and hearer diverge, or when the hearer happens not to be paying attention to the speaker’s words, the reference of the indexical fails.
2. Kaplan: Intentionalism
Claim. Kaplan argues that the necessary and sufficient condition for an impure indexical to refer to object $c$ is that the speaker uses the indexical with a directing intention to refer to $c$.
Problem. When the speaker’s directing intention can be infinitely flexible, the Humpty Dumpty problem arises. For instance, provided the speaker has sufficient intention, the speaker could point to a photograph of Donald Trump and refer to Rudolf Carnap, which is highly counterintuitive.
Kaplan also presents the following complex Humpty Dumpty case:
A philosophy teacher had hung a photograph of Rudolf Carnap behind the lectern. However, one day a mischievous student secretly replaced Carnap’s photograph with one of Donald Trump. Unaware of this fact, when students entered the classroom, the teacher pointed behind himself and said “That is one of the greatest philosophers of the 20th century”.
In the above case, the teacher has the intention to refer to Rudolf Carnap’s photograph with the indexical ‘that’, but the hearers (the students) cannot grasp this intention. This raises the question: is the teacher’s utterance true or false?
According to strong intentionalism, since the teacher uttered ‘that’ with the intention to refer to Carnap, ‘that’ refers to Carnap, and therefore the teacher’s utterance is true.
3. Gricean Intentionalism
Gail Stine provides a different solution to Kaplan’s dilemma by grafting Grice’s semantics onto intentionalism. For indexical $i$ to successfully refer to object $c$, the speaker must have three intentions: the speaker must 1) have the intention to refer to $c$ with $i$, 2) have the intention to get the hearer to identify $c$ as the referent with $i$, and 3) have the intention to get the hearer to identify $c$ as referent through the hearer’s recognition of the speaker’s intention.
Gricean intentionalism resolves the Humpty Dumpty problem. To resolve Kaplan’s Humpty Dumpty problem, Stine presents the distinction between direct reference and indirect reference. In Kaplan’s case, the teacher has the intention to refer to Rudolf Carnap, but this intention is achieved through the intention to refer to the picture behind him. Therefore, the former is indirect reference and the latter is direct reference. Stine argues that when indirect referent and direct referent conflict, the direct referent takes priority. That is, the teacher’s statement is false.
4. Reimer-style Intentionalism
Gricean intentionalism has the limitation(?) that it cannot eliminate the Humpty Dumpty problem in cases of speakers with sufficiently strange beliefs, such as ‘a speaker who believes the other party can read their mind’.
In response, Reimer takes a different strategy for constraining intentionalism, which can be summarised as gesture priority. Reimer’s constrained intentionalism appears to resolve many more Humpty Dumpty problems than expected with remarkable clarity.
지시에 대하여 — 기술주의와 인과 이론
07 Jan 2025해당 글은 스탠퍼드 철학백과의 지시 항목을 요약 및 정리한 글이다.
1. 서론
”저것은 금성이다“, “영국의 마지막 여왕은 엘리자베스 2세이다”에서 ‘저것‘, ’금성’, ’영국의 마지막 여왕‘, ‘엘리자베스 2세’는 이 세상에서 오직 하나의 대상을 특정하여 지시하는 표현들이다. 그러나 이들 표현이 특정 대상을 지시하게 되는 구체적 원리는 철학적 의문으로 가득하다.
이 글에서 다루는 질문은 여섯 가지이다.
- 지시의 주체: 화자인가 단어인가?
- 지시 표현의 의미: 기술구인가, 지시체인가, 그 외의 것인가?
- 지시의 메커니즘: 지시 표현은 어떻게 특정 인물/대상에 결부되는가?
- 지시 이론의 범위: 모든 지시 표현은 공통의 메커니즘을 가지는가?
- 지시의 사적성: 지시는 화자의 사적 특징(e.g. 심리 상태)에 얼마나 의존하는가?
- 지시 이론의 의의: 지시 관계라는 것이 실제로 있는가? 철학적으로 유의미한가?
이 글에서 다루는 이론은 기술주의, 인과 이론, 특성 모델, 의도주의의 네 가지이며, 추가로 지시 회의주의를 짧게 다룬다.
| 기술주의 | 인과 이론 | 특성 모델 | 의도주의 | |
|---|---|---|---|---|
| 주체 | 화자 | 지시어 | 다원적 | 화자 |
| 의미 | 기술적 내용 | 지시체 | 특성과 내용 | |
| 메커니즘 | 단어는 구체적인 기술적 내용과 결부되어 그에 부합하는 대상을 지시한다. | 단어는 지시체의 명명식으로 거슬러 올라가는 인과적 사슬과 결부되어 지시한다. | 단어는 통상적 지시 규칙(특성)과 결부되어 대상(내용)을 지시한다. | 단어는 특정 대상을 지시하려는 의도와 결부되어 지시한다. |
| 범위 | 넓음 | 좁음(이름) | 보통 | 넓음 |
| 사적성 | 강한 사적성 | 약한 사적성 | 보통 사적성 | 강한~보통 사적성 |
| 학자 | (프레게), 러셀, 스트로슨, 라이헨바흐 | 밀, 크립키, 캐플런 | 캐플런 | 캐플런, 그라이스, 라이머 |
| 강점 | 프레게의 퍼즐을 설명 | 크립키의 논증을 해결 | 순수지표사의 원리를 해명 | 불순지표사의 원리를 해명 |
| 단점 | 크립키의 양상 논증 및 의미론적 논증 | 다수의 담지자를 가지는 이름의 문제 | 불순지표사에서 화자-청자 딜레마 발생 | 험티덤티 문제 |
2. 고유이름
2.1. 고유이름에 대한 기술주의 이론
기술주의 논제.
- 고유이름 $n$은 특정 기술적 내용 $P$와 결부된다.
- $n$이 $P$와 결부되는 이유는 화자가 마음속에서 $n$을 $P$와 결부하기 때문이다.
- $P$를 만족하는 대상 $c$가 유일하게 존재할 때, $n$은 $c$를 지시한다.
- $n$의 의미와 $n$의 지시체는 구별되며, 전자가 후자를 결정한다.
- $n$의 의미는 $P$이다.
예를 들어 ‘금성‘이라는 이름에 “태양계의 두 번째 행성”이라는 기술적 내용을 결부하는 화자는, 해당 기술적 내용을 만족하는 대상이 유일하며 그 대상이 금성이기 때문에 ’금성‘을 사용하여 금성을 지시한다.
Remark.
-
기술적 내용은 기술구로 이해하는 것이 표준적이지만, 설(Searle) 등은 기술적 내용이 언어적으로 명시 가능한 것뿐 아니라 지각에 기반할 수도 있다고 주장한다.
-
기술적 내용은, 그것을 만족시키는 대상이 불변한다는 특징을 가진다. 후술하다시피 이것은 기술주의가 지표사를 적절히 설명하지 못하는 원인이다.
-
$n$의 의미는 대언적이다. 후술하다시피 이것은 기술주의가 양상 반론에 직면하는 원인이다.
-
1번, 3번, 4번, 5번 논제는 이름의 의미론 — 즉, 이름을 정의역으로 가지는 의미 함수 $M$의 공역이 무엇인지 설명하는 이론 — 을 제공하고, 2번 논제는 이름의 메타의미론 — 즉, 각 이름 $n$에 대해 사상 $n \mapsto M(n)$은 어떻게 정의되는지 설명하는 이론 — 을 제공한다.
논변 1. 여러 담지자를 가지는 이름의 사례
A와 B가 ’보리스 존슨‘이라는 이름을 가진 두 명의 사람을 아는 경우를 고려하자. 한 명은 A와 B의 직장 동료이고, 다른 한 명은 영국의 전 총리이다. A가 B에게 “보리스 존슨은 중대한 실수를 저질렀다.”라고 말하자, B는 “어느 보리스 존슨을 의미하는가?”라고 묻는다. 이에 대해 A는 “영국의 전 총리”라고 대답한다.
위 사례에서 ’보리스 존슨‘이 지시하는 바는 (1) 화자인 A에게 결정권이 있으며, 이 결정은 (2) 화자가 마음속으로 염두에 두고 있는 기술적 내용을 매개로 이루어지는 것으로 보인다.
논변 2. 프레게의 퍼즐
다음 예문을 보자.
- 샛별은 개밥바라기이다.
- 산타클로스는 북극에 산다.
- 프레드는 마크 트웨인이 미국인이었다고 믿지만 새뮤얼 클레먼스가 미국인이었다고는 믿지 않는다.
1은 참이지만 선험적(a priori)이지 않다. 2는 무의미(nonsense)하지 않다. 3의 경우 프레드의 믿음은 정합적(consistent)이다.
만약 이름의 의미가 그 지시체라면 1은 자기동일성 법칙에 따라 선험적이어야 하고, 2는 지시체(의미)가 결여된 문장이므로 무의미해야 하고, 3의 경우 마크 트웨인과 새뮤얼 클래먼스의 의미가 같으므로 프레드의 믿음은 비정합적이어야 한다. 그러나 기술주의는 이름의 의미와 지시체를 구별함으로써 세 예문에 대한 적절한 설명을 내놓는다.
반론 1. 양상 논증
만약 내가 ‘보리스 존슨’에 대해 “브렉시트를 시행한 영국의 전 총리”라는 기술구를 결부시킨다 해도 나는 아래 문장을 참이라고 주장할 수 있다.
1. 보리스 존슨은 브렉시트를 시행하지 않을 수 있었다.
그러나 이름의 의미가 기술구와 동등하다면 1은 2와 동치이다.
2. 다음이 사실일 수 있었다: 브렉시트를 시행한 영국의 전 총리는 브렉시트를 시행하지 않았다.
그러나 2는 거짓이다. 따라서 이름의 의미는 기술적 내용이 아니다.
Remark. 이름의 의미가 대상(re)이 아닌 기술적 내용(dicto)이므로, 1 → 2는 De Dicto 치환이다. De Re 치환의 경우 1은 3이 된다.
3. 브렉시트를 시행한 영국의 전 총리가 $c$일 때, 다음이 사실일 수 있었다: $c$는 브렉시트를 시행하지 않았다.
2와 달리 3은 참으로 간주하는 데 문제가 없다.
Remark. 양상 논증에 대처하기 위해 기술주의자는 3번, 4번 논제를 수정하고 5번 논제를 기각할 수 있다.
-
$P$를 만족하는 대상 $c$가 현실 세계에서 유일하게 존재할 때, $n$은 $c$를 지시한다.
-
$n$의 의미는 $n$의 지시체, 즉 $c$이다. (즉, $n$의 의미는 대물적이다)
그러나 이렇게 수정된 기술주의는 프레게의 퍼즐을 적절히 설명하지 못할 뿐더러, 다음의 의미론적 논증 또한 적절히 설명하지 못한다는 점에서 한계가 많은 이론이다.
반론 2. 의미론적 논증
의미론적 논증은 방금 제시한 수정 기술주의를 비롯, 기술주의에 속하는 일군의 이론을 반박하는 논증이다. 요지는, 많은 경우 화자가 이름 $n$에 결부하는 기술적 내용 $P$는 세계에서 특정 대상을 유일하게 집어내지 못하며(즉, 기술은 불충분하며), 애초에 기술적 내용은 지시에 불필요하다는 것이다.
먼저 기술적 내용이 불충분함을 보여주는 사례로서 크립키가 제시한 파인만-겔만 사고실험이 있다. 대부분의 사람이 ‘파인만’이라는 이름에 결부하는 기술적 내용은 “미국의 유명한 물리학자” 정도이다. 이는 겔만 또한 해당하는 기술이다. 그러나 우리는 ‘파인만’이라는 이름으로 파인만을 성공적으로 지시하는 듯하다.
나아가 기술적 내용이 불필요함을 보여주는 사례로서 마찬가지로 크립키가 제시한 괴델-슈미트 사고실험을 보자. 크립키는 다음의 상황을 가정한다.
사실 산술의 불완전성을 처음 증명한 수학자는 괴델이 아닌 슈미트라는 무명의 수학자다. 그러나 증명을 발표하기 전, 슈미트는 의문스러운 죽음을 당했고 그의 증명은 괴델의 손에 들어가 괴델의 이름으로 발표되었다.
(이 괴상한 사고실험에 대해서는 자기보다 위대한 논리학자인 괴델을 시기했던 크립키의 분풀이라는 카더라가 전해진다)
만약 (P1) 위 가정이 사실이고, (P2) 기술주의가 올바르며, (P3) 대부분의 사람이 ’괴델‘이라는 이름에 결부하는 기술적 내용이 ”산술의 불완전성을 처음 증명한 수학자“라면, (C) 대부분의 사람이 ’괴델‘이라는 이름으로 지시하는 대상은 괴델이 아닌 슈미트라는 결론이 도출된다. 그러나 이것은 반직관적이다. 따라서 기술주의는 올바르지 않다.
Remark. 의미론적 논증을 극복하기 위해기술주의자는 다음 두 노선 중 하나를 택할 수 있다.
-
이름에 결부되는 기술적 내용은 화자에게 개인적으로 이용 가능한 정보를 초월할 수 있다.
-
이름에 결부되는 기술적 내용으로 “나에게 이 이름을 전달해 준 사람이 그 이름으로 지시하고자 했던 사람”을 채택할 수 있다.
스트로슨은 1번 노선을 선택한다. 그에 따르면 화자는 이름과 결부되어야 하는 기술적 내용을 제시하는 작업을 타인에게 의존할 수 있다. 이 경우, ‘파인만’ 또는 ‘괴델’의 의미는 파인만 전문가, 또는 괴델 전문가가 각 이름에 결부하는 기술적 내용이다. 그러나 스트로슨주의는 화자의 지시 의도를, 실제로 이루어지는 지시와 무관한 것으로 만든다는 점에서 반직관적이라는 한계가 있다.
2번 노선은 인과 이론과 밀접하게 닿아있다. 해당 이론을 살펴보도록 하자.
2.2. 고유이름에 대한 밀주의 및 인과 이론
밀주의 논제. 고유이름의 의미는 곧 지시체이다.
“밀주의”라는 이름에서 알 수 있듯이 이 입장은 존 스튜어트 밀로 거슬러 올라간다. 밀주의 이론들은 “샛별은 개밥바라기이다”와 같은 동일성 진술이 후험적이지만 필연적으로 참임을 함의한다.
Remark. 크립키는 선험적이지만 우연적으로 참인 문장 또한 존재한다고 주장하며, “미터 원기의 길이는 1m이다”를 그 사례로 든다.
밀주의 논제는 이름에 대한 의미론을 제공한다. 이를 보충하는 대표적인 메타의미론으로 인과 이론이 있다.
인과 이론.
- 처음으로 대상 $c$를 이름 $n$으로 부르는 사건인 명명식이 있다.
- 명명식에 참여한 사람을 시초로 하여, $n$으로 $c$를 지시하는 화자는 의사소통을 통해 해당 용례를 다른 화자에게 전달한다. 이같은 용례의 전달은 이름의 인과적 사슬을 형성한다.
- 이름 $n$의 의미(지시체)는 $n$의 인과적 사슬의 시발점에 이루어진 명명식에서 명명된 대상이다.
인과 이론의 미묘한 문제 중 하나는 어떤 의사소통 전달이 인과적 사슬에 실질적으로 참여하는지를 구별하는 문제이다. 일례로 내가 직장 동료에게 거만한 나의 고양이를 ’나폴레옹‘으로 불렀다고 해서 이 의사소통이 ’나폴레옹‘이라는 이름의 인과적 사슬에 실질적으로 참여하지는 않는다(이름의 가식적 사용). 또한 마다가스카르 사례와 같이 이름의 지시체가 도중에 바뀌는 경우도 있다(이름의 혼동된 사용). 여기서는 이 문제에 대한 논의를 생략한다.
2.3. 다수의 담지자가 있는 이름의 문제
앞선 ‘보리스 존슨‘의 사례와 같이 다수의 담지자가 있는 이름의 경우, 지시의 결정권은 화자에게 있는 듯하다. 이 사실은 고전적 기술주의의 경우 문제가 되지 않는다. 그러나 스트로슨주의와 인과 이론에게 이 문제는 골칫거리이다.
스트로슨주의의 경우 이름 $n$의 지시체는 전문가 집단에 의해 유일하게 결정되므로 최대 1개의 지시체만을 가질 수 있다. 그러나 다수의 담지자가 있는 이름이 분명 가능하므로, 스트로슨주의는 이름을 더 세분화해서 생각해야 한다. 즉, 문자적으로 동등하지만($\ulcorner n_1 \urcorner = \ulcorner n_2 \urcorner$) 의미론적으로 다른($n_1 \mapsto c_1, n_2 \mapsto c_2, c_1 \neq c_2$) 이름들이 가능하다고 보는 것이다. 그러나 이 경우, 화자가 $\ulcorner n_i \urcorner$를 발화할 때 $i$를 결정하는 원리가 무엇이냐는 문제가 생긴다. 해당 원리가 화자의 내면 기술구일 수는 없는데, $\ulcorner n_i \urcorner$을 사용하여 $c_1$ 또는 $c_2$를 지시할 수 있으나 $c_1$과 $c_2$를 구별해 내는 데 충분한 지시적 내용을 갖추지 못한 화자를 떠올릴 수 있기 때문이다.
필자는 이탤릭체 내용을 받아들이지 못했다. 그런 경우가 정말로 있나?
밀주의에도 비슷한 문제가 발생한다. 이 문제를 극복하기 위해 캐플런은 이름을 심리 현상으로 간주한다. 즉, 이름 $n$은 문자적 내용 $\ulcorner n \urcorner$과, $\ulcorner n \urcorner$으로 $c$를 지시하려는 의도가 얽힌 심리 현상이며, 인과적 사슬을 통해 전달되는 것은 이 심리 현상이다. 이에 따르면 다수의 담지자를 가지는 이름은 $n_1 = (\ulcorner n \urcorner, c_1), n_2 = (\ulcorner n \urcorner, c_2)$과 같이 구별되는 이름이며, $n_1$과 $n_2$를 성공적으로 습득한 화자는 자신의 의도에 따라 $n_1$ 또는 $n_2$를 선택하여 사용할 수 있다.
캐플런과 구별되는 또 하나의 노선은 다수의 담지자 문제를 인과 이론과 지표사 이론의 혼합으로 해결하려는 시도이다. 이 노선은 르카나티, 펠처, 래인스버리 등에 의해 채택되었으며, 다음 글에서 살펴 볼 지표사 이론에 대한 이해를 요구한다.
On Reference — Descriptivism and Causal Theory
07 Jan 2025This post was originally written in Korean, and has been machine translated into English. It may contain minor errors or unnatural expressions. Proofreading will be done in the near future.
This article is a summary and analysis of the Stanford Encyclopedia of Philosophy entry on reference.
1. Introduction
In “That is Venus” and “The last Queen of England is Elizabeth II”, the expressions ‘that’, ‘Venus’, ‘the last Queen of England’, and ‘Elizabeth II’ are expressions that refer to exactly one object in this world by specifying it. However, the specific principles by which these expressions come to refer to particular objects are shrouded with philosophical puzzles.
This article addresses six questions:
- The subject of referring: Is reference done by the speaker via their intention, or by the word via its meaning?
- The meaning of referring expressions: Is it a (defininte) description, the referent, or something else?
- The mechanism of reference: What grounds the correspondence between referring expressions and referred objects?
- The scope of theories of reference: Do all referring expressions share a common mechanism?
- The privacy of reference: To what extent does reference depend on the speaker’s private states (e.g. intentions to refer)?
- The significance of theories of reference: Does the reference relation actually exist? Is it philosophically significant?
This article examines four theories: descriptivism, causal theory, character model, and intentionalism, and briefly discusses referential scepticism.
| Descriptivism | Causal Theory | Character Model | Intentionalism | |
|---|---|---|---|---|
| Subject | Speaker | Referring expression | Pluralistic | Speaker |
| Meaning | Descriptive content | Referent | Character and content | |
| Mechanism | Words are associated with specific descriptive content and refer to objects that satisfy them. | Words are associated with causal chains that trace back to the referent’s initial baptism. | Words are associated with conventional referential rules (character) to refer its referent (content). | Words are epiphenomenal to the speaker’s intention to refer to a specific objects. |
| Scope | Broad | Narrow (names) | Moderate | Broad |
| Privacy | Strong privacy | Weak privacy | Moderate privacy | Strong~moderate privacy |
| Scholars | (Frege), Russell, Strawson, Reichenbach | Mill, Kripke, Kaplan | Kaplan | Kaplan, Grice, Reimer |
| Strengths | Solves Frege’s puzzle | Solves Kripke’s arguments | Explains how pure indexicals work | Explains how impure indexicals work |
| Weaknesses | Kripke’s modal and semantic arguments | Problems with names having multiple bearers | Speaker-hearer dilemma arises with impure indexicals | Humpty Dumpty problem |
2. Proper Names
2.1. Descriptivist Theory of Proper Names
Descriptivist Thesis.
- A proper name $n$ is associated with specific descriptive content $P$.
- $n$ is associated with $P$ because the speaker privately (mentally) associates $n$ with $P$.
- When there exists a unique object $c$ that satisfies $P$, $n$ refers to $c$.
- The meaning of $n$ ($P$) and the referent of $n$ ($c$) are distinct, with the former determining the latter.
For example, a speaker who associates the name ‘Venus’ with the descriptive content “the second planet of the solar system” refers to Venus using ‘Venus’ because there is a unique object satisfying that descriptive content, and that object is Venus.
Remark.
-
while it is standard to understand descriptive content as descriptions, scholars such as Searle argue that descriptive content need not be linguistically specifiable but may also be based on perception.
-
The satisfaction relation of descriptive content is speaker-independent. As we shall see, this spells problem in explaining indexicals.
-
Furthermore, the satisfaction relation is de dicto. As we shall see, this spells problem in dealing with modality.
-
Theses 1, 3, 4 provide a semantics for names — a theory specifing the domain (names) and codomain (descriptive content) of the meaning function $M$ — while thesis 2 provides a metasemantics for names — a theory explaining how the map $n \mapsto M(n)$ is defined for each name $n$.
Argument 1. Cases of Names with Multiple Bearers
Consider a case where A and B know two people named ‘Boris Johnson’. One is a colleague of A and B, and the other is the former Prime Minister of Britain. When A says to B, “Boris Johnson has made a grave mistake,” B asks, “Which Boris Johnson do you mean?” To this, A replies, “The former Prime Minister of Britain.”
In the above case, it appears that (1) the speaker A has the authority to determine what ‘Boris Johnson’ refers to, and this determination is made (2) via the descriptive content that the speaker has in mind.
Argument 2. Frege’s Puzzle
Consider the following examples:
- The morning star is the evening star.
- Santa Claus lives at the North Pole.
- Fred believes that Mark Twain was American but does not believe that Samuel Clemens was American.
Let us first make some remarks. Statement 1 is true but not a priori. Statement 2 is not incomprehensible. Fred’s belief expressed in Statement 3 is not inconsistent.
If the meaning of a name were its referent, then 1 would be a priori by the law of self-identity, 2 would be nonsense as it has as its subject an expression lacking a referent, and in case 3, Fred’s belief would be inconsistent since Mark Twain and Samuel Clemens share the same referent. On the other hand, descriptivism provides adequate explanations for all three statements by distinguishing between the meaning and referent of names.
Objection 1. The Modal Argument
Even if I associate the description “the former British Prime Minister who implemented Brexit” with ‘Boris Johnson’, I can still assert the following sentence as true:
1. Boris Johnson might not have implemented Brexit.
However, if the meaning of a name is equivalent to a description, then 1 is equivalent to 2.
2. The following might have been the case: the former British Prime Minister who implemented Brexit did not implement Brexit.
But 2 is false. Therefore, the meaning of a name is not descriptive content.
Remark. Since the meaning of the name is de dicto, the inference from 1 to 2 is a de dicto substitution. In the case of de re substitution, 1 becomes 3.
3. Let $c$ be that person who is the former British Prime Minister who implemented Brexit. Then the following might have been the case: $c$ did not implement Brexit.
Unlike 2, there is no problem in regarding 3 as true. Hence, to deal with the modal argument, descriptivists may attempt to modify theses 3 and 4.
-
When there exists a unique object $c$ that satisfies $P$ in the actual world, $n$ refers to $c$.
-
The meaning of $n$ is the referent of $n$, i.e., $c$. (That is, the meaning of $n$ is de re)
However, this modified descriptivism not only fails to adequately explain Frege’s puzzle but also fails to adequately explain the following semantic argument, making it a theory with many limitations.
Objection 2. The Semantic Argument
The semantic argument is an argument that refutes a group of theories belonging to descriptivism, including the modified descriptivism just presented. The gist is that in many cases, the descriptive content $P$ that a speaker associates with a name $n$ fails to uniquely pick out a specific object in the world (i.e., the description is insufficient), and descriptive content is unnecessary for reference in the first place.
As a case showing that descriptive content is insufficient, there is the Feynman-Gell-Mann thought experiment presented by Kripke. The descriptive content that most people associate with the name ‘Feynman’ is something like “a famous American physicist”. This description also applies to Gell-Mann. However, we seem to successfully refer to Feynman with the name ‘Feynman’.
Furthermore, as a case showing that descriptive content is unnecessary, consider the Gödel-Schmidt thought experiment likewise presented by Kripke. Kripke assumes the following situation:
In fact, the mathematician who first proved the incompleteness of arithmetic was not Gödel but an unknown mathematician named Schmidt. However, before publishing the proof, Schmidt died under mysterious circumstances, and his proof fell into Gödel’s hands and was published under Gödel’s name.
(Regarding this bizarre thought experiment, there is a rumour that it was Kripke’s way of venting his jealousy towards Gödel, a logician greater than himself)
If (P1) the above assumption is true, (P2) descriptivism is correct, and (P3) the descriptive content that most people associate with the name ‘Gödel’ is “the mathematician who first proved the incompleteness of arithmetic”, then (C) the object that most people refer to with the name ‘Gödel’ is Schmidt, not Gödel. However, this is counterintuitive. Therefore, descriptivism is not correct.
Remark. To overcome the semantic argument, descriptivists can take one of two approaches:
-
The descriptive content associated with a name can transcend information personally available to the speaker.
-
The descriptive content associated with a name can adopt “the person whom the person who transmitted this name to me intended to refer to with that name”.
Strawson chooses approach 1. According to him, speakers can rely on others for the task of providing the descriptive content that should be associated with names. In this case, the meaning of ‘Feynman’ or ‘Gödel’ is the descriptive content that Feynman experts or Gödel experts associate with each name. However, Strawsonian theory has the limitation of being counterintuitive in that it makes the speaker’s referential intention irrelevant to the actual reference.
Approach 2 is closely connected to causal theory. Let us examine this theory.
2.2. Millianism and Causal Theory of Proper Names
Millian Thesis. The meaning of a proper name is its referent.
As the name suggests, this position traces back to John Stuart Mill. Millian theories imply that identity statements such as “The morning star is the evening star” are a posteriori but necessarily true.
Remark. Kripke also argues that there exist sentences that are a priori but contingently true, citing “The length of the standard metre is 1m” as an example.
The Millian thesis provides semantics for names. A representative metasemantics supplementing this is the causal theory.
Causal Theory.
- There is an initial baptism, an event in which object $c$ is first called by name $n$.
- Starting with those who participated in the initial baptism, speakers who refer to $c$ with $n$ transmit this usage to other speakers through communication. Such transmission of usage forms a causal chain of the name.
- The meaning (referent) of name $n$ is the object named in the initial baptism that occurred at the starting point of $n$’s causal chain.
One subtle problem with causal theory is distinguishing which communicative transmissions substantially participate in the causal chain. For instance, if I called my arrogant cat ‘Napoleon’ to a work colleague, this communication does not substantially participate in the causal chain of the name ‘Napoleon’ (parasitic use of names). There are also cases where the referent of a name changes along the way, such as the Madagascar case (confused use of names). We omit discussion of this problem here.
2.3. The Problem of Names with Multiple Bearers
In cases of names with multiple bearers, such as the earlier ‘Boris Johnson’ example, the authority to determine reference seems to lie with the speaker. This fact poses no problem for classical descriptivism. However, this
In cases of names with multiple bearers, such as the earlier ‘Boris Johnson’ example, the authority to determine reference seems to lie with the speaker. This fact poses no problem for classical descriptivism. However, this spells trouble for Strawsonian and causal theories.
In the case of Strawson’s theory, the referent of a name $n$ is uniquely determined by a group of experts, so it can have at most one referent. However, since names with multiple bearers are clearly possible, Strawson’s theory must consider names in a more nuanced way. That is, it must acknowledge the possibility of names that are literally equivalent ($\ulcorner n_1 \urcorner = \ulcorner n_2 \urcorner$) but semantically different ($n_1 \mapsto c_1, n_2 \mapsto c_2, c_1 \neq c_2$). However, this raises the question of what principle determines $i$ when the speaker utters $\ulcorner n_i \urcorner$. This principle cannot be the speaker’s internal description, as one can imagine a speaker who can refer to either $c_1$ or $c_2$ using $\ulcorner n_i \urcorner$, but lacks sufficient descriptive content to distinguish between $c_1$ and $c_2$.
I cannot accept the italicised content. Are there really such cases?
A similar problem arises in Millianism. To overcome this issue, Kaplan considers names as psychological phenomena. That is, a name $n$ is a psychological phenomenon intertwined with the literal content $\ulcorner n \urcorner$ and the intention to refer to $c$ using $\ulcorner n \urcorner$, and what is transmitted through the causal chain is this psychological phenomenon. According to this view, names with multiple bearers are distinguished as $n_1 = (\ulcorner n \urcorner, c_1), n_2 = (\ulcorner n \urcorner, c_2)$, and a speaker who has successfully acquired $n_1$ and $n_2$ can choose to use either $n_1$ or $n_2$ according to their intention.
Another approach that differs from Kaplan’s is the attempt to resolve the problem of multiple bearers through a combination of causal theory and indexical theory. This approach has been adopted by Lucanati, Pelcher, and Rainsbury, and requires an understanding of the indexical theory that will be examined in the following text.
대각선 논법 없이 실수의 비가산성 증명하기
26 Dec 2024정리. $\mathbb{R}$은 비가산이다. 즉, $\mathbb{N}$에서 $\mathbb{R}$로 가는 전사함수는 존재하지 않는다.
수학과 2학년 정도 되면 한번쯤은 들어 봤을 정리이다. 가장 널리 알려진 증명은 칸토어의 대각선 논법이다. 하지만 대각선 논법 없이 이 정리를 증명하는 방법이 있다. 각각 $\mathbb{R}$의 순서적 특징과, 위상적 특징을 이용한다.
1. 동형성 정리를 이용한 증명
칸토어의 동형성 정리에 따르면 다음을 만족하는 전순서 집합 $(S, \leq)$는 모두 순서 동형이다.
- $S$는 가산이다.
- $S$는 조밀하다. 즉, $x, y \in S$에 대해 $x < y$라면 $x < z < y$인 $z \in S$가 존재한다.
- $S$는 상계 및 하계를 가지지 않는다.
$(\mathbb{Q}, \leq)$는 위 세 조건을 모두 만족하고, $(\mathbb{R}, \leq)$는 2와 3을 만족한다. 따라서 만약 $\mathbb{R}$이 가산이면 $(\mathbb{R}, \leq)$는 $(\mathbb{Q}, \leq)$와 순서 동형이다. 하지만 전자는 완비인데 반해 후자는 그렇지 않으므로 $\mathbb{R}$은 비가산이다. ■
2. 콤팩트성을 이용한 증명
$X$가 고립점이 없는 콤팩트한 하우스도르프 공간이라고 하자. 또한 $X \neq \varnothing$이라고 하자.
Claim 1. $U \neq \varnothing$가 $X$의 열린 집합이라고 하자. $x \in X$에 대해 $x \notin \bar{V}$이면서 $V \subset U$인 열린 집합 $V$가 존재한다.
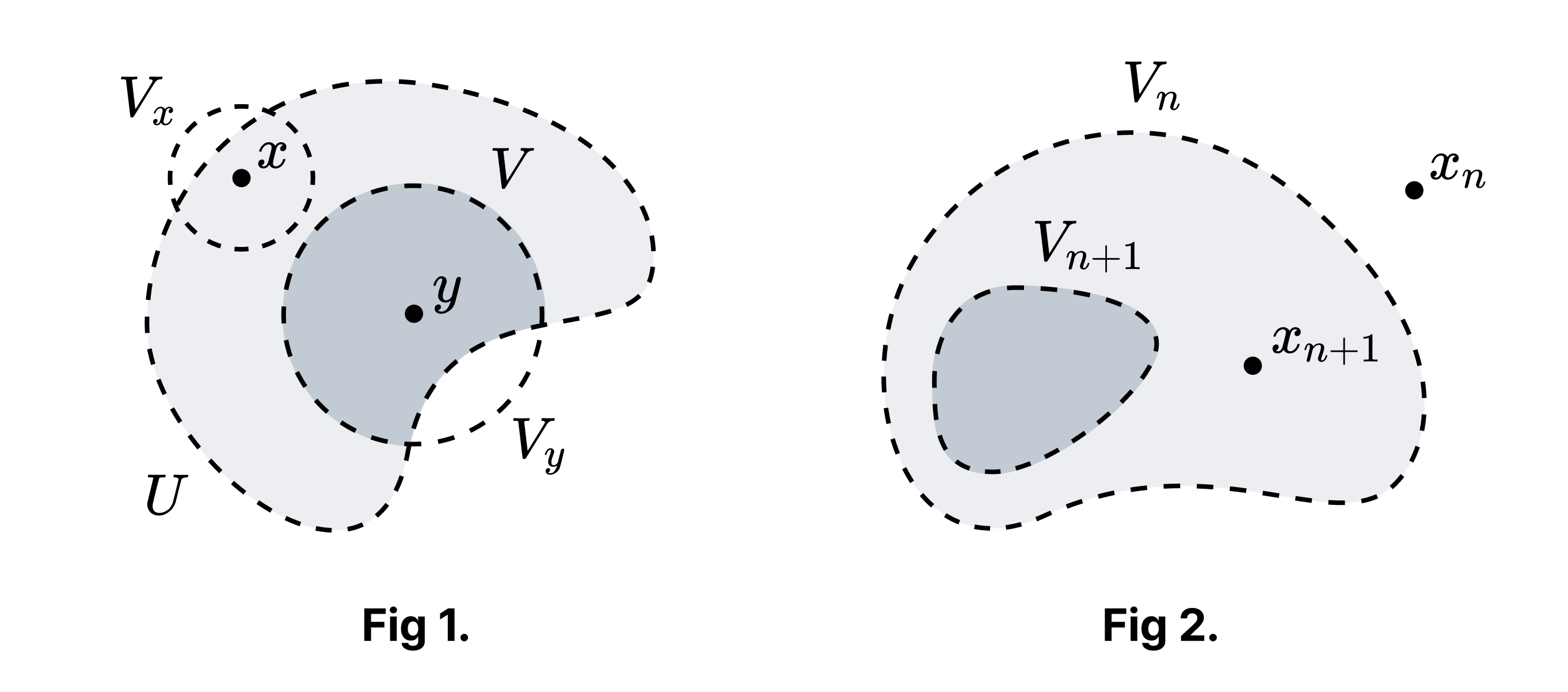
Proof of Claim 1. $x \neq y$이며 $y \in U$가 존재한다. 왜냐하면 $x \in U$인 경우 $X$가 고립점을 가지지 않으므로 존재하고, $x \notin U$인 경우 $U$가 공집합이 아니기 때문에 존재하기 때문이다. $X$가 하우스도르프이므로 $x, y$를 근방 $V_x, V_y$로 분리할 수 있다. $V = V_y \cap U$가 얻고자 하는 집합이다 (Fig 1에서 짙게 색칠된 영역). □
Claim 2. $X$는 비가산이다.
Proof of Claim 2. $X$가 가산이라고 하자. $X$의 원소들을 $\lbrace x_n \rbrace_{n \in \mathbb{Z}^+}$와 같이 나열한다. $V_0 = X$라고 하자. Claim 1에 의해 각 $n$에 대해 $x_n \notin \bar{V_n}$인 열린 집합 $V_n$이고 $V_n \subset V_{n-1}$인 열린 집합 $V_n$이 존재한다 (Fig 2). $X$가 콤팩트하므로 유한 교집합 성질에 의해
\[K = \bigcap_{n \in \mathbb{Z}^+} \bar{V}_n \neq \varnothing\]이다. 하지만 $x_n \in K$라면 $x_n \in \bar{V}_n$이 되어 모순이다. 따라서 $X$는 비가산이다. □
Claim 3. $\mathbb{R}$은 비가산이다.
Proof of Claim 3. $[0, 1]$은 고립점을 가지지 않는 콤팩트 하우스도르프 공간이다. 따라서 비가산이다. 이에 따라 $\mathbb{R}$은 비가산이다. ■